県教委は「新型コロナウイルス感染拡大による外出自粛や、スマートフォンやゲームの長時間利用で日々の運動時間が減ったことが影響したとみられる。子どもの運動意欲を高める取り組みを推進する」
せっかく、条例を作ったのに、あまり効果がでないようだ。
スマホやゲームなどの利用時間に関する質問では、長時間利用する子どもほど実技測定の得点が低い傾向が表れた。特に、平日1日の利用が「5時間以上」と答えた子どもの平均得点は、小中学校の男女全てで最も低かった。
旧版294ページから。普及版311ページから。
292-293ページの写真から。 ディスタンクシオンには写真が並ぶところがあるが、説明が基本的にはない。

ベレー帽の起源はバスク地方にある。バスク地方の肉屋(Boucher du Pays basque)で検索すると、下記のような写真がみつかる。

必ずしも肉屋の店員すべてがベレー帽被っているわけではないが、今も似たような形で肉屋が営まれているようだ。
ただ、服装で違う点がある。現代の肉屋はだいたいの人がエプロンをつけているところが、ディスタンクシオンに掲載された男性はエプロンをつけていない。それがどのような意味を持つのかまではわからなかった。

データ整理をしている女性。
カードというと図書館の目録カードではないか、と思うのだか、そうでもないようだった。
日本の目録カードはアメリカ議会図書館をベースに作られたとのことである。
アメリカ議会図書館について書かれた記事。
1枚目の写真は目録カードの引き出しである。日本と同じく1列1つの引き出しで構成されている。
2枚目の写真は議会図書館の業務についての説明とその風景である。
2枚目の写真が興味深い。
アメリカ議会図書館は、新しく出版された本の目録を作成すると同時に、その記述情報を他の図書館と共有していた。1901年から何十年もの間、図書館がその情報を共有するために使用していた形式は、目録カードでした。この何百万枚もの目録カードを作成し、印刷し、整理し、保管し、配布するために、米国議会図書館では何百人ものスタッフと、下の写真のような広大なスペースが必要であった。(棚やテーブルの上にある何千もの箱が見えるだろうか? 図書館で印刷された目録カードであふれている)。
議会図書館は目録カードの作成した上で、全国の図書館へ配布するという作業をしていたようだ。
フランスの目録カードはWikipediaにまとめが載っていた。
日本も、アメリカも、フランスも基本的にすべて同じ形で管理しているようだった。
国際標準カードサイズがあり、縦75mm、横125mmのもののようだ。
ということで、ディスタンクシオンに掲載された女性は図書館ではなく、一般の事務作業の風景であることだろうという結論になった。


おそらくワインのぶどう集めの道具に似ているので、ぶどうかわからないが、何らかの作物を後ろに入れて作業しているだろうことがわかる。
服装で気になるのは帽子である。この帽子の正しい名称はよくわからないが、キャスケットの一種ではないか、ということだった。
フランスの例ではないが19世紀のイギリスを描いたシャーロックホームズの冒険(グラナダTV版)のオープニングをみてみよう。

新聞売りはつばの短い帽子を被っている。

新聞を買いに来た人はシルクハットを被っている。ホームズの連載は『ストランド・マガジン』という雑誌であるが、当時のロウアー・ミドル・クラスに好まれたのは新聞も雑誌も同じである。当時から続く新聞としては『デイリー・メール』が有名だろう。このような出版物を買っているということは、ジェントリー階級ではなく、ロウアー・ミドル・クラスなのだろう。

あまり金を持ってなさそうな少年たちはつばの短い帽子を被り、警官は一目で警官とわかる帽子を被っている。

最後に御者の帽子である。おそらく黄色いラインが特徴であり、こちらも一目で御者であることが分かるようになっている。
日本では警察やコックさんが職業を示す帽子を被っていることは理解できるが、帽子と階級といわれてもピンと来ない。階級を表す帽子という発想がなかったので、何度も観たはずのこのオープニングで見えていなかったものが多かったことを実感した。
字にも文化資本があるという話。
鄧小平のサインがキレイだという話になったので確認してみた。

毛沢東はどうかというと以下。

では、蒋介石はというと以下。

鄧小平は蒋介石的というよりも、毛沢東的な署名である。毛沢東のふるまいをその後の指導者が真似た可能性もある。
日本の政治家でひときわ目立っているのは福島瑞穂である。

これは「変体少女文字」なのでは?ということで以下の本。
これを機に『変体少女文字の研究』を読んでみた。福島さんの字は明らかに変体少女文字の特徴がみられる。この本の仮説ではシャープペンシルの普及と横書きへの対応として変体少女文字が現れたというものであった。民や党の「はね」は横書きの場合、次の文字にいち早く移れるような書き方がされているので、福島さんの字は横書きをし続けた結果なのだろう。

日本の政治家すべてが字に無頓着ということではないようだ。
志位和夫の色紙。

党首だけを調べただけなので、確かなことは言えないが、左翼政党では署名をきれいに書くことは重要視されていないようである。
297ページ、普及版316ページから。
この例では、for-loopを使ってベクトル上をループする方法を説明する。
i in 1:10: iの中に1]から10までを代入していく
i^2: 計算式
for(i in 1:10) { # for文ヘッド
x1 <- i^2 # コードブロック
print(x1) # 結果Print
}
結果。
[1] 1 [1] 4 [1] 9 [1] 16 [1] 25 [1] 36 [1] 49 [1] 64 [1] 81 [1] 100
Rのforループは、通常の配列に対して反復するのではなく、オブジェクトの集合に対して反復することを理解することが非常に重要である。そのため、文字列のベクターに対してループをかけることができる。
文字型のベクターを作成。
x2 <- c("Max", "Tina", "Lindsey", "Anton", "Sharon") # 文字ベクターの作成
nchar(i): 文字数を数える
for(i in x2) { # 文字ベクターのループ関数のヘッド
print(paste("The name", i, "consists of", nchar(i), "characters."))
}
結果。
[1] "The name Max consists of 3 characters." [1] "The name Tina consists of 4 characters." [1] "The name Lindsey consists of 7 characters." [1] "The name Anton consists of 5 characters." [1] "The name Sharon consists of 6 characters."
各forループの反復の出力をベクトルに連結するため、まず空のベクトルを作成する。
x3 <- numeric() # 空のデータオブジェクトを作成する
for文を使って、出力値のベクトルを作る。
for(i in 1:10) { # for分のヘッド
x3 <- c(x3, i^2) # コードブロック
}
結果。
x3 # 結果Print # [1] 1 4 9 16 25 36 49 64 81 100
for-loopはネストされたループでよく使用される。例4では、forループを別のforループの中に入れ子にする方法を紹介する。 まず、別の空のベクトルを作成する(例3と同様)。
x4 <- character() # 空のデータオブジェクトを作成する
次のような入れ子のforループを使って、各ベクトル要素に2つの(異なる)アルファベットが含まれるベクトルを作成することができる。
for(i in 1:5) { # 最初のfor-loopのヘッド
for(j in 1:3) { # ネストされたfor-loopのヘッド
x4 <- c(x4, paste(LETTERS[i], letters[j], sep = "_")) # コードブロック
}
}
x4 # 結果Print
結果。
"A_a" "A_b" "A_c" "B_a" "B_b" "B_c" "C_a" "C_b" "C_c" "D_a" "D_b" "D_c" "E_a" "E_b" "E_c"
forループの中に論理的なif条件を指定し、それがTRUEになった場合にループの実行を停止させることができる。 この例では、i >=5 という条件を満たしたときにループを停止させる方法を説明する。if条件の中でbreak文を使う。
for(i in 1:10) { # for-loopのヘッド
x5 <- i^2 # コードブロック
print(x5) # 結果Print
if(i >= 5) { # 条件付きでfor-loopを停止する
break # breakステートメントの使用
}
}
結果。
[1] 1 [1] 4 [1] 9 [1] 16 [1] 25
例5と同様にnext文でforループの繰り返しをスキップすることもできる。次のforループは、インデックス位置1、5、7でスキップされる。
for(i in 1:10) { # for-loopのヘッド
if(i %in% c(1, 5, 7)) { # 条件付きスキップ反復
next # next文の使用
}
x6 <- i^2 # コードブロック
print(x6) # 結果Print
}
結果。
[1] 4 [1] 9 [1] 16 [1] 36 [1] 64 [1] 81 [1] 100
この例では、データフレームの変数をループで処理する方法を説明する。まず、irisデータをロードしてみよう。
data(iris) # irisのデータセットの読み込み head(iris) # Sepal.Length Sepal.Width Petal.Length Petal.Width Species # 1 5.1 3.5 1.4 0.2 setosa # 2 4.9 3.0 1.4 0.2 setosa # 3 4.7 3.2 1.3 0.2 setosa # 4 4.6 3.1 1.5 0.2 setosa # 5 5.0 3.6 1.4 0.2 setosa # 6 5.4 3.9 1.7 0.4 setosa
この例のデータフレームには、アヤメの花に関する情報からなる5つの列が含まれています。iris_new1 という新しいデータフレームオブジェクトにデータを複製する。
iris_new1 <- iris # irisデータセットの複製
ここで、for文の先頭でncol関数を使って、データフレームの列をループさせることができるforループの中では、論理的なif条件も使用している。
greplは文字ベクトルに一致させる関数(参考: https://www.delftstack.com/ja/howto/r/grepl-in-r/ , https://r-lang.com/grepl-in-r/)
ncol(iris_new1): 変数の数(列数)を数える
grepl("Width", colnames(iris_new1)[i]): colnames(iris_new1)=変数名の中から、"Width"の含まれるものに限定し
iris_new1[ , i]: iris_new1のi列目
iris_new1[ , i] + 1000: 列に1000を加算
for(i in 1:ncol(iris_new1)) { # for-loopのヘッド
if(grepl("Width", colnames(iris_new1)[i])) { # 論理条件
iris_new1[ , i] <- iris_new1[ , i] + 1000 # コードブロック
}
}
更新されたデータフレーム。
head(iris_new1) # Sepal.Length Sepal.Width Petal.Length Petal.Width Species # 1 5.1 1003.5 1.4 1000.2 setosa # 2 4.9 1003.0 1.4 1000.2 setosa # 3 4.7 1003.2 1.3 1000.2 setosa # 4 4.6 1003.1 1.5 1000.2 setosa # 5 5.0 1003.6 1.4 1000.2 setosa # 6 5.4 1003.9 1.7 1000.4 setosa
例8では、forループの中で変数名を作成したり変更したりする方法を紹介する。もう一度、irisの元のデータフレームを複製しよう。
iris_new2 <- iris
ここで、colnames と paste0 関数を適用して、データフレームの各列に新しい列名を作成することができる。
for(i in 1:ncol(iris_new2)) { # for-loopのヘッド
colnames(iris_new2)[i] <- paste0("new_", i) # コードブロック
}
結果。
head(iris_new2) # new_1 new_2 new_3 new_4 new_5 # 1 5.1 3.5 1.4 0.2 setosa # 2 4.9 3.0 1.4 0.2 setosa # 3 4.7 3.2 1.3 0.2 setosa # 4 4.6 3.1 1.5 0.2 setosa # 5 5.0 3.6 1.4 0.2 setosa # 6 5.4 3.9 1.7 0.4 setosa
ごのように、データフレームの列には接頭辞 "new_"とデータフレーム内での位置の名前が付けられている。
for-loopは、数行のコードで複数のプロットを効率的に描画したい場合に非常に便利である。例えば、irusデータフレームの各数値列のプロットを描きたい場合を考えてみよう。すると、次のようなRコードが使えます。
ncol(iris): 列数のカウント nrow(iris): 行数のカウント
for(i in 1:(ncol(iris) - 1)) { # for-loopのヘッド
plot(1:nrow(iris), iris[ , i]) # コードブロック
Sys.sleep(1) # コード実行の一時停止
}
先のRコードで作成した最終的なプロットを図1に示す。グラフを描画した後、1秒待つように指定していることに注意してほしい。これは、GIFファイルを作成する場合にも有効である。 for-loopでデータをプロットするための、より高度なチュートリアルを作成した。このチュートリアルはggplot2パッケージ(Rのグラフィックのための非常に強力なパッケージ)についてもカバーしている(https://statisticsglobe.com/print-ggplot2-plot-within-for-loop-in-r)。
これまでの例では、ベクターやデータフレームにfor-loopを適用してきた。この例では、リストオブジェクトの操作のためにfor-loopをどのように書き、使用するかを紹介する。 まず、リストの例を作成する。
my_list <- list(1:5, # サンプルリストの作成
letters[3:1],
"XXX")
my_list # print例のリスト
# [[1]]
# [1] 1 2 3 4 5
#
# [[2]]
# [1] "c" "b" "a"
#
# [[3]]
# [1] "XXX"
このリストは3つの異なるリスト要素から構成されている。length関数を使って、リスト上をループすることができる。
for(i in 1:length(my_list)) { # for-loopのヘッド
my_list[[i]] <- rep(my_list[[i]], 3) # コードブロック
}
結果。
my_list # Print アップデートしたリスト # [[1]] # [1] 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 # # [[2]] # [1] "c" "b" "a" "c" "b" "a" "c" "b" "a" # # [[3]] # [1] "XXX" "XXX" "XXX"
各リストの要素を3回複製している。
背景
重度の調節障害を持つ子どもは、さまざまな障害や精神病理を同時に、また長期的に経験することになり、特に気分障害や不安障害のリスクが高い。児童行動チェックリスト調節障害プロファイル(CBCL-DP)は、高度な調節障害を持つ子どもを特定するのに有用であり、早期の介入を促す可能性がある。
研究方法
破壊的行動のために評価と治療のためにクリニックに紹介された6~12歳の小児348人を対象に,CBCL-DPの2つのカテゴリー定義の有病率,性差,親と教師の一致,および並行性の妥当性を検討した。
結果
CBCL-DPの定義を厳しくしない場合と厳しくした場合では、CBCL-DPを満たす割合が3倍高かった(46.8% vs. 15.2%)。CBCL-DPのより厳格な定義を用いた場合、女子の方が男子よりもCBCL-DPの基準を満たす可能性が高かった。保護者と教師の合意は、特にCBCL-DPのより厳格な定義を用いた場合に低かった。CBCL-DPを持つ子供は、CBCL-DPの定義にかかわらず、また、CBCLの他の下位尺度で臨床的に高い得点を持つ子供と比較しても、教師ではなく、両親から他の子供よりも障害があると評価された。
制限事項
今回の横断的データでは、CBCL-DPの予測的妥当性を検討することができなかった。また、情報提供者の効果により、CBCL-DPと親が評価した障害との関連性が高くなっている可能性があり、多くの子どもについて教師の評価が欠けていた。
CBCL-DPの論文だが、どのようなニーズがあって書かれたものかがよくわからなかった。
感情、行動、および/または認知の重度の調節障害は、小児期に精神病理学および精神社会的障害の可能性を高め、成人期には人格障害を含む精神病理学の割合を高めることと関連している(Jucksch et al.,2011; McGough et al.,2008; Meyer et al.,2009)
CBCL-DP(Dysregulation Profile Score)は、児童行動チェックリスト(CBCL; Achenbach and Rescorla, 2001; Althoff et al., 2010)のAnxious/Depressed、Attention Problems、Aggressive Behavior syndromeの各尺度のTスコアを合計することで算出される。CBCL-DPは、もともと双極性障害の子どもを識別するために開発されたものである(Althoff、2010; Biederman et al.)CBCL-DPは、小児の双極性障害を同定する精度には限界があるが(Ayer et al.,2009; Diler et al.,2009; Mbekou et al.,2014; Volk and Todd, 2007)、小児や青年における調節障害や精神病理の重症度のマーカーとしての有用性が示されている(Althoff,2010; Holtmann et al.,2011; Kim et al.,2012)。因子分析研究では,CBCL-DPの3因子構造が支持されており,また,2因子モデルでは一般的な調節障害因子が同定されている(Deutzら,2016;Geeraertsら,2015;Haltiganら,2018)。 CBCL-DPスコアは、5年スパンで0.66~0.77の相関があり、小児期から成人期にかけて中等度から高度に安定(Boomsmaら、2006年)、小児期から成人期にかけても安定している(McQuillanら、2018年)。
破壊的行動の有病率は男子よりも女子のほうが低いが、破壊的行動のある女子は男子よりも重篤な影響を受けるというジェンダーパラドックスと一致する(Loeber et al., 2000)
潜在クラス分析を用いてCBCL-DPを同定した1つの研究からの証拠は,親と教師の間の一致は統計的に有意だが低いことを示唆しており(Althoff et al., 2011),子どもの精神病理の他の尺度における親と教師の一致に関する多くの証拠と一致している(Achenbach et al., 1987; De Los Reyes and Kazdin, 2005)。
CBCLおよびTRF症候群尺度は、高い内部一貫性(CBCLではα=0.78~0.94、TRFではα=0.72~0.95)、テスト・リテスト信頼性(CBCLではrs=0.82~0.92、TRFではrs=0.60~0.95)、評価者間一致度(TRFではrs=0.65~0.85、rs=0.28~0.69)などの信頼性を示した。CBCLとTRFのシンドローム・スケール・スコアもまた、紹介された子どもと紹介されなかった子どもを有意に区別し、CBCLスコアは紹介状況の分散の20〜33%を占め(ps<0.01)、TRFスコアは紹介状況の分散の10〜22%を占めた(ps<0.01;ただし、CBCLとTRFの身体的愁訴スコアは、多重比較を補正しても紹介状況の有意な予測因子ではなかった;Achenbach and Rescorla, 2001)。 同様に、CBCLのCompetenceとTRFのAdaptiveスコアについても、内部一貫性(それぞれα=0.79とα=0.90)、テスト・リテストの信頼性(それぞれr=0.91とr=0.93)、評価者間の一致(それぞれr=0.68とr=0.55)が高くなっています。 また、CBCLのCompetenceとTRFのAdaptiveのスコアは、紹介された子どもとそうでない子どもを有意に区別する(紹介状況を予測する分散のそれぞれ36%と29%を占める、ps < 0.001; Achenbach and Rescorla, 2001)。
従属変数の分布が正規分布から著しく乖離していること,CBCL-DP-70を持つ子どもと持たない子どもでグループサイズが大きく異なること,変数によってはグループ間で誤差分散が著しく異なることから,ロバスト最尤推定量を用いました(Muthén and Muthén, 2012)。
半数近く(46.8%)の子どもが、より寛容なCBCL-DP-210の基準を満たしており、性別とCBCL-DP-210の状態との間には、χ2(1, n = 348) = 3.22, p = 0.07という有意な差は見られませんでした。一方、CBCL-DP-70の基準を満たしていたのは15.2%で、女子は男子に比べてCBCL-DP-70の基準を満たしている割合が有意に高かった(χ2(1, n = 348) = 6.83, p = 0.01, 女子の25%、男子の13%)。
これまでの因子分析の結果、CBCL-DPスコアは、より広範な一般精神病理因子(Haltiganら、2018年)の代理である可能性が示唆されており、この因子は精神病理症候群全体に共通する基礎的な次元を表すと考えられている(Caspiら、2014年)
マルチグーループSEMをMplusで行う。データはHolzingerSwineford1939を用いる。Mplus用のデータへの変換は下部参照のこと。
今回は配置不変モデルのみ。
Grant-White学校のSEMのダイアグラム。
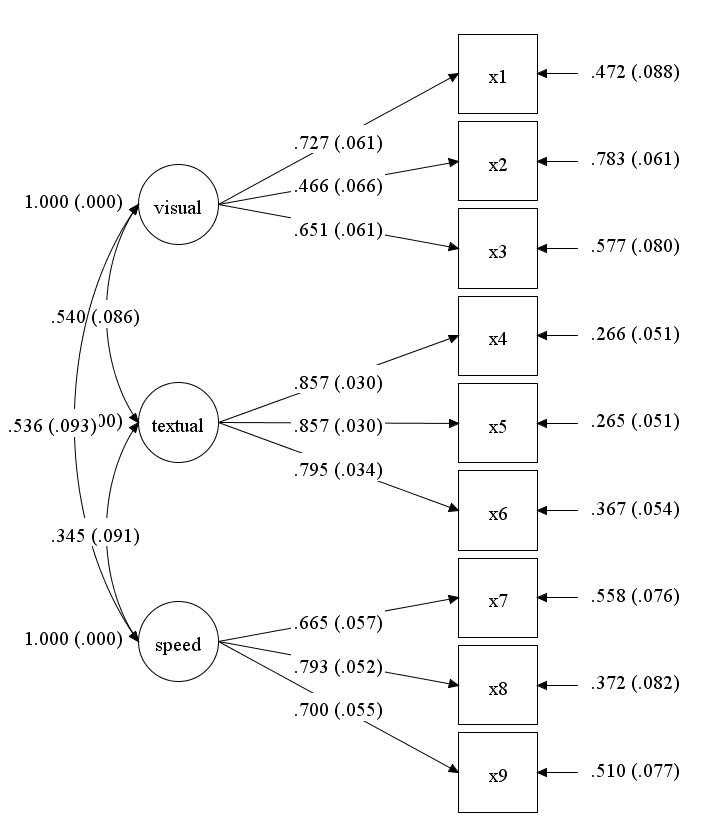
TITLE: Multiple Group SEM using HolzingerSwineford1939 Data DATA: FILE = "HolzingerSwineford1939.dat"; LISTWISE = ON; VARIABLE: NAMES = id sex ageyr agemo school grade x1 x2 x3 x4 x5 x6 x7 x8 x9; USEVARIABLES = x1 x2 x3 x4 x5 x6 x7 x8 x9; GROUPING = school (1=Grant-White, 2=Pasteur); MISSING=.; Analysis: TYPE = GENERAL; ESTIMATOR = ML; ITERATIONS = 200; MODEL = NOMEANSTRUCTURE; INFORMATION = EXPECTED; MODEL: visual by x1 x2 x3; textual by x4 x5 x6; speed by x7 x8 x9; OUTPUT: SAMPSTAT STDYX;
Group GRANT-WHITE
VISUAL BY
X1 0.727 0.061 11.957 0.000
X2 0.466 0.066 7.080 0.000
X3 0.651 0.061 10.598 0.000
TEXTUAL BY
X4 0.857 0.030 28.579 0.000
X5 0.857 0.030 28.614 0.000
X6 0.795 0.034 23.414 0.000
SPEED BY
X7 0.665 0.057 11.710 0.000
X8 0.793 0.052 15.298 0.000
X9 0.700 0.055 12.706 0.000
TEXTUAL WITH
VISUAL 0.540 0.086 6.317 0.000
SPEED WITH
VISUAL 0.536 0.093 5.733 0.000
TEXTUAL 0.345 0.091 3.781 0.000
Group PASTEUR
VISUAL BY
X1 0.771 0.063 12.153 0.000
X2 0.432 0.063 6.893 0.000
X3 0.600 0.061 9.901 0.000
TEXTUAL BY
X4 0.823 0.031 26.218 0.000
X5 0.824 0.031 26.256 0.000
X6 0.860 0.029 29.410 0.000
SPEED BY
X7 0.514 0.059 8.710 0.000
X8 0.679 0.063 10.726 0.000
X9 0.577 0.060 9.558 0.000
TEXTUAL WITH
VISUAL 0.484 0.087 5.600 0.000
SPEED WITH
VISUAL 0.340 0.114 2.994 0.003
TEXTUAL 0.333 0.100 3.342 0.001
Rで実行する。
library(lavaan) data(HolzingerSwineford1939) df1 <- HolzingerSwineford1939
library(MplusAutomation) variable.names(df1)
prepareMplusData(df1, filename="HolzingerSwineford1939.dat", overwrite=T)
目的
CBCLの小児双極性障害(PBD)プロファイルは、臨床医のイデオロギー的バイアスを回避するために親が記入する指標である。CBCLは注意欠陥・多動性障害(ADHD)患者の鑑別に有用であることが証明されている。我々は、CBCL-PBDプロファイルを用いて、ADHDに罹患した複数の兄弟姉妹を対象としたゲノムワイドスキャンにおいて、併存疾患のパターンを識別し、量的形質遺伝子座(QTL: quantitative trait loci)を探索した。
方法
5~18歳のADHD患者540名を対象に、Kiddie Schedule for Affective Disorders and Schizophrenia (KSADS-PL)とCBCLで評価した。両親は、破壊的行動障害についてKSADSを補足したSchedule for Affected Disorders and Schizophrenia (SADS-LA)で評価した。CBCL-PBDプロファイルに基づいて、精神疾患の併存パターンを対比した。QTL分散成分分析を用いて、CBCL-PBDの量的表現型に対する感受性遺伝子が存在する可能性のあるゲノム領域を同定した。
結果
双極性スペクトラム障害は全体の2%未満であった。CBCL-PBDの分類は,全般性不安障害(p=.001),反抗性反抗障害(p=.008),行為障害(p=.003),親の物質乱用(p=.005)の増加と関連していた。染色体2qに中程度の有意な連鎖シグナル(多点最大LODスコア、MLS=2.5)が認められた。
結論
CBCL-PBDプロファイルは、重大な併存疾患を持つADHD患者のサブセットを区別する。CBCL-PBD表現型の連鎖分析は、重度の精神病理を引き起こしやすい遺伝子をさらに調査する価値のある特定のゲノム領域を示唆している。
注目すべきは、CBCL-PBD群では、CBCL-コントロール群やCBCL-AP群に比べて、双極性障害と診断された割合が3~5倍になっていることである。
CBCLが有効ということなのだろう。 ともあれ、遺伝研究は知識がないのでよくわからない。
2q21.1についてはこちら。
自閉症、発達障害、てんかん、注意欠陥多動性障害(ADHD)などの患者において、2番染色体の一部に欠失や重複がある
2q21.1には、GPR148、FAM123C、ARHGEF4、FAM168B、PLEKHB2の5つの遺伝子が含まれている
対応のあるt検定に対応したノンパラメトリック検定。ウィルコクソンの順位和検定Wilcoxon rank-sum testとは異なる。
wilcoxon.test (variable1, variable2, Paired=TRUE)
Wilcoxon W検定統計量は、単純に最小の順位の合計だが、p 値(Asymp.Sig)を計算するために、Rは標準正規分布の近似を使用して、結果の p 値を出す。結果のp値この近似は、正確な検定がより信頼できるような小さなサンプルの場合には信頼性に欠ける。サンプルが少ない場合は"exact=FALSE"を"exact=TRUEに"変更する。フィッシャーの正確確率検定Fisher.test()と同じような要領である。
絶対的な(正の)標準化検定統計量zをペアの数の平方根で割ってエフェクト・サイズをだすこともできる。Rでは標準化検定統計量を出力されないが出力のp値を使って計算できる。
test<-wilcoxon.test(variable1 , variable2, paired = TRUE,exact=FALSE) ## 標準化したz統計量を計算し`Zstat`に格納。P値は`test$p`で呼び出せる。 Zstat<-qnorm(test$p.value/2) ## エフェクト・サイズの計算 abs(Zstat)/sqrt(! enter pair number)
参考までに対応のない検定の方も。Two-sample testである。"Paired=FALSE"はデフォルトなので指定しなくてもよいが、明示的にするために書いておこう。。
wilcox.test(variable1, avariable2, Paired=FALSE)
データを指定する場合の書式。
wilcox.test(variable1 ~ avariable2, data=data)
https://www.sheffield.ac.uk/polopoly_fs/1.714576!/file/stcp-marquier-WilcoxonR.pdf

