
- 作者: 斎藤環
- 出版社/メーカー: 日本評論社
- 発売日: 2019/07/09
- メディア: 単行本
- この商品を含むブログを見る
ひきこもりとオープンダイアローグのところを少し読ませていただきました。ネットワークを復活させるための支援、一対一で支援をするよりも一対数人で支援をする方が効果的というのはまったくその通りだと思いました。オープンダイアローグ全般はあま知らないので勉強させていただきます。
ひきこもりとオープンダイアローグのところを少し読ませていただきました。ネットワークを復活させるための支援、一対一で支援をするよりも一対数人で支援をする方が効果的というのはまったくその通りだと思いました。オープンダイアローグ全般はあま知らないので勉強させていただきます。
Mplusでの平行分析の実行の仕方は以前に書いたが、Rでも実行できる。
今回もbfiデータの1~25列目を使用する(参考: http://ides.hatenablog.com/entry/2019/03/19/093726)。
library("psych")
data(bfi)
d1<-bfi[1:25]
平行分析は次のように指定する。
fa.parallel(d1)
"Parallel analysis suggests that the number of factors = 6 and the number of components = 6"と出力され6因子、6成分と提案があった。 今まで行ってきた他の方法よりも因子数が多い印象である。

ちなみに図にあるPCとは" principal components"のことで、主成分分析FAはprincipal axis factor analysisで主因子法のことである。
オプションとしてfa="minres"のように表記して、minres(最小残差法), ml(最尤法), uls(重みづけのない最小二乗法), wls(重み付き最小2乗法), gls(一般化最小二乗法), pa(主成分)が指定できる。デフォルトはminresである。
対角SMC平行分析はオプションで指定を行う。
fa.parallel(d1, SMC=TRUE)
こちらは8因子を提案がされてきた。
堀啓造先生によると下記のような特徴があるらしい。
対角に SMC 入れた分析(SMC-EIGEN)の場合、ほかの推定法に比べ極端に多くの因子数を推測する。
対角SMC の平行分析はその点それ以上の因子をとってはいけないという指標となりうるのである。
欠点としてはマイナー因子も拾うことがあるので,まったく因子を想定しない項目群では多めの因子数を推定する。
https://www.ec.kagawa-u.ac.jp/~hori/yomimono/nfac.ppt
たしかに今回のシミュレーションでも最も多い因子数を提案してきた。
因子分析をしていて混同しがちなのは因子負荷(因子パターン)と相関係数ではないかと思う。

誰も教えてくれなかった因子分析: 数式が絶対に出てこない因子分析入門
この2つを直観的に区別するのに役に立つのが松尾・中村(2002)にある図2.5.6である。

これは2因子を想定、斜交回転をした図である。 第1因子と第2因子は45°くらいで交わっている。
因子負荷は軸と並行に下ろしてきたところの数値である。 一方で、相関係数は軸と90°直角に下ろしてきたところの数値である。
このため、因子負荷と相関係数は異なった値となわけだが、直交行回転の場合は同じ値となる。
因子負荷とは技法的には相関係数ではあるが、実際に相関係数とは別の値になることがこの図でわかるのではないだろうか。この図も含めてこの本は直観的に因子分析が理解できる良書だと思う。
探索的因子分析において因子数を決定する基準として使われるMAPについて。
MAP:Minimum Average Partial correlationであり、日本語だと最小平均偏相関になる。
Velicerによつて開発された方法である。
因子数を決める基準はどれが適切かという議論は比較的多くされているようだ。
下記の論文ではMAPについて次のように書かれている。
http://www.glmj.org/archives/articles/Pearson_v39n1.pdf
試験1では、VelicerのMAPはある程度良好であった;しかし、PA-R、BIC、LRTほどではありませんが、BICやPA-Rと同様に、変動率が小さい場合には過小評価される可能性があった。また、過小評価はBICやPA-Rよりも変動率に影響をうける。その傾向は研究2でより厳しく、この知見はZwickとVelicer(1986)のそれと類似していた。 したがって、MAPを用いている研究者は、特に変動因子比が低い場合には、この方法が示唆するよりも1つまたは2つ多い因子を用いたモデルを試した方が良いかもしれません。一般的な統計パッケージではMAPも並行分析も標準的な選択肢ではないため、これらのいずれか外部ツールを使うことになる。分析者は代わりに共通因子並行分析を試みるべきである。
この論文ではAICの結果が良かったとされている。
少なくとも、AIC>BICであるのは確かなようだ。
ともあれRを用いたMAPの出し方を書いておこう。
psychパッケージのVSS()で計算することができる。
library(psych) data(bfi) d1 <- bfi[1:25]
IPIP-NEOのデータを使用する。IPIP-NEOの詳細はこちら 5因子5問ずつのデータを使うので1~25列目までをd1に格納した。
res01<-vss(d1) print(res01,digits =4)
偏相関の値がわりと同じような数値になりやすいため、小数点以下を4桁に調整してみた。
VSSはどれが提案されたのかがちゃんと文章で出るようになっている。
The Velicer MAP achieves a minimum of 0.0148 with 5 factors
ということで5因子が提案されたようだ。
MAP基準の推定方法を指定できるようだ。
vss(data, fm="minres") #最小残差法 vss(data, fm="mle") #最尤法 vss(data, fm="pc") #主成分
Rでの方法はこちらを参照。
データはRのpsychパッケージに含まれるものを利用するので、作成方法は下部に記載する。 (追記: 2021/12/06) データの内容についてはこちらを参照。
TITLE:
Exploratory Factor Analysis by Mplus, using IPIP-NEO data.
DATA:
FILE = "bfi.dat";
VARIABLE:
NAMES = A1-A5 C1-C5 E1-E5 N1-N5 gender education age;
USEVARIABLES = A1-A5 C1-C5 E1-E5 N1-N5;
MISSING = .;
ANALYSIS:
TYPE = EFA 3 6;
ESTIMATOR = ML;
ROTATION = oblimin;
PARALLEL = 50;
PLOT:
TYPE = plot2;
OUTPUT:
residual;
DATA:
データを置いた場所を指定する。日本語のフォルダ内に入れない方が良い。データのエンコードはUTF-8にしておこう。
VARIABLE:
今回使うのはA1からN5の25個のデータ。
ANALYSIS:
EFAとはExploratory Factor Analysisの省略。
3 6となっているのは、3因子モデルから6因子モデルを検討するという意味。
推定法はML、回転はオブリミオン回転を指定している。回転を指定しない場合のデフォルト値はオブリミオン回転なので、指定はしなくてもよい。
PARALLELは平行分析のサンプリング数。この数を大きくすると、計算が長くなるのでほどほどにしておこう。Mplusのマニュアルでは50回と例示されてある*1が、 Finch & Bolin(2017)では1000という例示がある(p.177)のでマシンパワーがあれば大きい数字でもよいのだろう。
PLOT:
スクリープロットの出力を指定。
まず因子数を決めることから始める。 とはいっても、このデータの妥当な因子数はよくわからない。
RESULTS FOR EXPLORATORY FACTOR ANALYSIS
EIGENVALUES FOR SAMPLE CORRELATION MATRIX
1 2 3 4 5
________ ________ ________ ________ ________
4.729 2.581 2.019 1.468 0.979
固有値1を超えるのは4因子モデルである。5因子モデルになると0.979と1を切るため、固有値を1以上とするガットマン基準からは4因子モデルが提案される。
モデルのフィッティングを見てみよう。
SUMMARY OF MODEL FIT INFORMATION
Degrees of
Model Chi-Square Freedom P-Value
3-factor 2794.270 133 0.0000
4-factor 1376.733 116 0.0000
5-factor 903.210 100 0.0000
6-factor 649.008 85 0.0000
Degrees of
Models Compared Chi-Square Freedom P-Value
3-factor against 4-factor 1417.537 17 0.0000
4-factor against 5-factor 473.523 16 0.0000
5-factor against 6-factor 254.203 15 0.0000
Models Comparedのところをみると、モデルが改善されたかがわかる。改善しなくなったところで打ち止めをするのが通常である。具体的にはカイ二乗検定のP値をみる。例えば、6因子モデルのP値が0.360とかになっていると、モデルが改善していないとして、一つ前の5因子モデルを採用する。
ただ、実際には6因子モデルも0.000なので、5→6因子モデルにすることによってフィッティングは改善していることになっている。
追記(2021/12/05)
Bengt O. Muthenは下記の記述があった。
http://www.statmodel.com/discussion/messages/8/26371.html?1539133417
このような矛盾したメッセージは、実際のデータでもよく起こる。なぜなら、データは、ある数の因子を持つ完全な因子モデルを表していない可能性があるからである。例えば、m個の因子があっても、いくつかの残差相関がある場合がある。この場合、カイ二乗はmよりも多くの因子を持つべきだとでますが、これは本当のモデルではない。これは、いくつかの因子が2つの有意な負荷量しか持たないことでよく現れる。残差相関が存在するかどうかを確認するために、修正指数を見てほしい。一般的には、平行分析の方がこの問題に強いかもしれないが、これが徹底的に研究されているかどうかはわからない。そしてもちろん、どのような解決策がトピックの理論とどのように関連しているかを確認する必要がある。
Velicer(1976)のMinimum Average Partial(MAP)はMplusのオプションには含まれないようだ*2。
MAPの値を出せるのは、服部先生の「忍者はっとりくん」、清水先生のHAD、RのpsychパッケージにあるVSS()関数のようだ。MAPのデータが必要な時には別のプログラムが必要である。
| Model | BIC |
|---|---|
| 3-factor | 184190.261 |
| 4-factor | 182907.658 |
| 5-factor | 182561.134 |
| 6-factor | 182425.992 |
BICは小さいほうがフィッティングがよいとされている。微妙に数値が現象して行っているが、6因子が最も小さく、値も劇的に改善しているとも言いづらいため、あまり参考にはならなさそうである。
ちなみに、BICはプロマックス回転では出力されない。
下の図はスクリープロットと平行分析の図である。
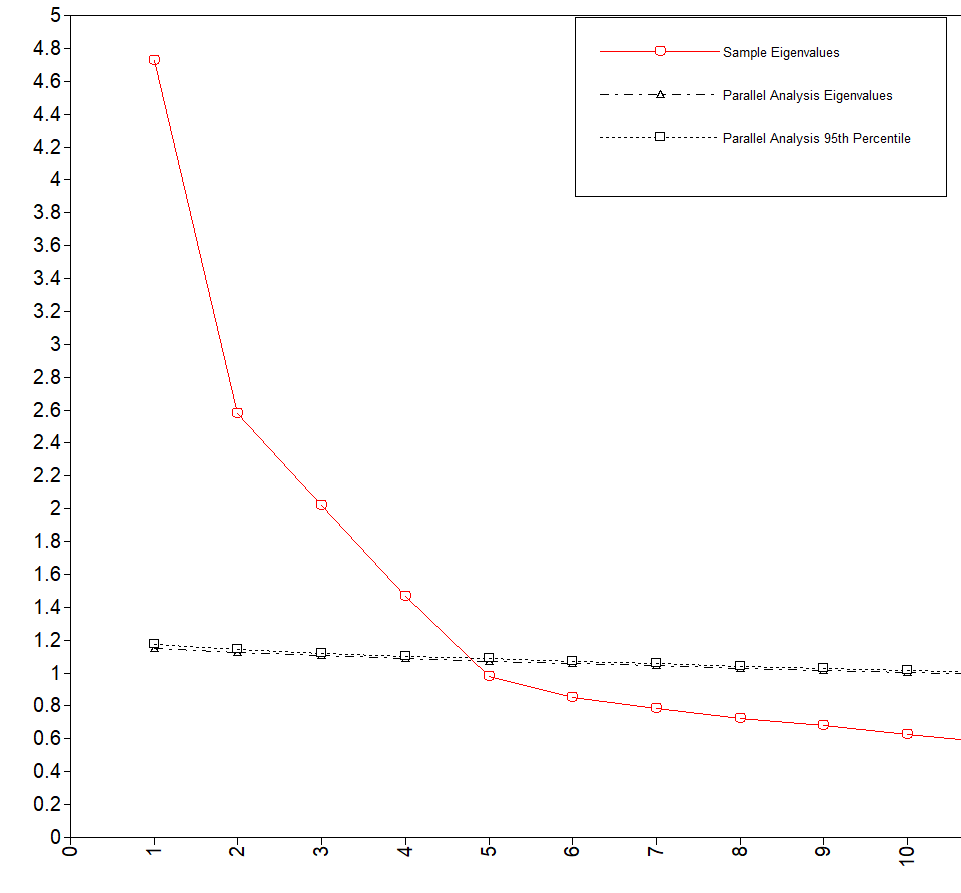
スクリープロットは推移がなだらかになる前までの数値を採用するので、4因子モデルが良さそうである。
黒色の斜め横点線より上側の因子数を採用する方法である。清水先生のブログでちゃんと説明されているのでま詳しい解説はそちらで。
このデータの場合は4因子モデルが支持されている。
基準を総合すると4因子モデルがよさそうである。
このデータはNEOなのでもともとは5因子モデルのデータであったはずなのだが、統計量は4因子モデルを指示している。
")
Rで作成する。
library("psych")
data(bfi)
df1 <- bfi
df1$A1<-as.numeric(df1$A1) df1$A2<-as.numeric(df1$A2) df1$A3<-as.numeric(df1$A3) df1$A4<-as.numeric(df1$A4) df1$A5<-as.numeric(df1$A5) df1$C1<-as.numeric(df1$C1) df1$C2<-as.numeric(df1$C2) df1$C3<-as.numeric(df1$C3) df1$C4<-as.numeric(df1$C4) df1$C5<-as.numeric(df1$C5) df1$E1<-as.numeric(df1$E1) df1$E2<-as.numeric(df1$E2) df1$E3<-as.numeric(df1$E3) df1$E4<-as.numeric(df1$E4) df1$E5<-as.numeric(df1$E5) df1$N1<-as.numeric(df1$N1) df1$N2<-as.numeric(df1$N2) df1$N3<-as.numeric(df1$N3) df1$N4<-as.numeric(df1$N4) df1$N5<-as.numeric(df1$N5) df1$O1<-as.numeric(df1$O1) df1$O1<-as.numeric(df1$gender) df1$O1<-as.numeric(df1$education) df1$O1<-as.numeric(df1$age)
この作業はMplusAutomation()がnumericでないとうけつけないため。
library(MplusAutomation) variable.names(df1) # 変数名を書き出し prepareMplusData(df1, filename="bfi.dat", overwrite=T)
*1:http://www.statmodel.com/download/usersguide/Chapter16.pdf
*2:No, Mplus doesn't do that MAP test. posted by Bengt O. Muthen, http://www.statmodel.com/discussion/messages/8/20916.html?1429281795
")
ユースケ・サンタマリアはある時期、うつ病であったようだ。
文庫版でユースケ・サンタマリアのインタビューが追加されている。他のインタビューに答えている人はうつ病かよくわからないが、ユースケ・サンタマリアに関しては比較的重症のうつ病であったようだ。
ユースケ 病院に行くと異常なしで、「じゃあストレスだ」って心療内科とかに行かされるわけですよ。そうすると、欝じゃないのにそういうとこに行くことになっちゃった人って、先生からいろいろ言われたときに芝居しちゃうっていうか、そっちに引きずられちゃうんですよ。先生が僕の目とかじっと見ながらしゃべってるんだけど、ちょっと目線をキョドらせてみたりとか(笑)。人間のわけわかんないところなんだけど、その場に乗っかっちゃう。
吉田 なぜか期待に応えようとしちゃうわけですね(笑)。
ユースケ そう。で、やっぱり「ちょっと欝の気があるね」って抗欝剤とか出されちゃって、知り合いにその薬を見せたら「絶対に飲まないほうがいい。こんなもん飲んだらホントに病気になっちゃうよ」って言われて。だから飲んでないんだけど、そんな薬でこの症状が治まるんなら飲もうかな、みたいな。藁にもすがるような思いで、占い師みたいな人に診てもらったりね。宗教に走る人の気持ちがちょっとわかったというか。「わかります。誰でもそうなりますよ」とか言われると信じちゃうんだから。弱ってると信じちゃうんですよね。だからちょっと高い授業料を払って。で、ホントに悪かったのは五年ぐらいです、ゲロゲロで。
占い師には見てもらったが、抗うつ剤は飲まなかったらしい。
実際のところはわからないが、抗うつ剤を入れていたら、簡単に治っていたように思う。抗うつ剤を入れるとずっと飲まないといけないというのは誤りで、うつ病がなおっていれば、比較的簡単に抜くことができる。
ずっと抗うつ薬を飲んでいる人というのは、うつ病が治っていないから飲んでいるだけにすぎない。惰性で飲んでいる人もいるとは思うが。
抗うつ剤を飲んだら「ホントに病気になっちゃうよ」というのは、原因と結果が逆転している。病気だから薬を飲むのである。
抗うつ剤への抵抗はまだまだ大きいようだ。
うつ状態にあるときのエピソード。
ユースケ でも、その頃って周りみんな元気だから、「どうしたの?ユースケさん!美味い寿司屋あるから行こうよ!」って、とにかく俺を元気づけたいから。「気分悪いから寿司なんて一番食えないんだよ」って話なんだけど、でもそれ言うと向こうが「ああ・・・そう」みたいな感じで二度と連絡ないですから。「せっかく人が元気づけようとしてやってるのに断りやがった」「後輩のくせに」とか思われちゃう。俺は飯が食えないし、人と会ったりするテンションじゃないんだよ、動けないんだもん。
吉田 「そんなときは美味しい御飯食べれば元気が出るよ」と言われでも・・・。
ユースケ そう、「肉行こう肉!」みたいな。それが一番食えないのに。
よくある話。
宮本輝のエッセイに「パニック障害がもたらしたもの」というものがある。
")
宮本輝がパニック発作を初めて経験した時は次のように書かれてある。
もうじき淀駅に着くというころ、私は自分がいつもの自分とは違うことに気づいた。自分が自分でないような、神経の焦点が合っていないような、理由もなくかすかな恐怖感が心のなかでかすかに波立っているような、そんな感覚がつづいたあと、私は不意に全身が地の底に沈んでいきそうになって、慌てて電車の座席に両手を突いて支えた。
電車は何の支障もなく走りつづけている。何等かの事故が起こったのではなく、異変が生じたのはこの自分なのだとすぐにわかった。
その途端、どうにも抑えようのない、耐えられないほどの不安と恐怖がせりあがってきた。視界が白っぽかった。
自分にいったい何事が生じたのか、さっぱりわからなくて、とにかくいっときも早く電車から降りたいと思っているうちに、眩暈(めまい)と耳鳴りがして、不安感はさらに強まり、動悸(どうき)が頭の芯にまで響き始めた。全身から血の気が引き、掌が汗で濡れていくのも感じた。
電車の中でパニック発作を初めて経験したようだ。
翌日、私は会社の近くにある病院で診てもらった。
(中略)
「何か悩み事はない?」
「借金がありますねェ。秋に結婚するんですが、その費用を使い込んで、結婚相手にばれんうちに穴埋めしようと思って、きのう競馬場に行こうとしてたんです」
なかなかいい感じのクズっぷりである。
ここで終わると宮本輝をディすってるるようにも読めるので、一応全体の骨子を述べると、パニック障害になってサラリーマンが続けられなくなり、小説家になるしかないと考えた。必死に頑張って小説を仕上げて、世の中に評価されるようになったという感じの流れである。パニック障害があるから小説家として大成したという良い?話。