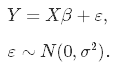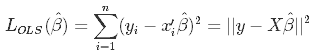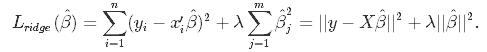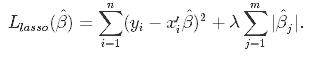2値のカテゴリカル因子分析と2値の潜在クラス分析の結果どのように違うのかをシミュレーションしてみたい。因子分析も潜在クラス分析もグループ分けをする手技である。しかし、両者はグループの分け方が異なる。因子分析が変数の近さでグループを作るのに対して、潜在クラス分析はケースのパターンでグループを作成する。
今回使うデータはいつも使っているIPIP-NEOである。データの性質は以前に書いているのでこちらを参照してほしい。
データの作成
library("psych")
data(bfi) # IPIP-MEO のデータ
d1 <- bfi[1:25] # 因子分析に使用するのは1~25列目
library(OneR)
d2 <- bin(d1, nbins = 2, labels = c(1,2)) #2分位
library(dplyr)
d3 <- d2 %>% mutate_if(is.factor, as.integer) # 整数型への変換
d1が順序変数のデータ、d2が2値のfactor型データ、d3が2値の整数型のデータである。
因子数の決定
もともと5因子のデータだが、因子数の決定についても見ていこう。
平行分析
fa.parallel(d1)
fa.parallel(d3)
MAP情報量
R_map<-vss(d3)
print(R_map,digits =4)
R_mapC<-vss(d1)
print(R_mapC,digits =4)
順序変数では平行分析は6因子、MAP情報量は5因子を提案をしている。
2値データでは平行分析は6因子、MAP情報量は2因子を提案をしている。
MAP情報量は順序変数や連続変数では比較的良い因子数の提案をしてくれるが、2値では正確に推定するのはと難しいのかもしれない。このデータでは、平行分析の方が良い提案をしているように思える。
クラス数の決定
潜在クラス分析のクラス数はどうだろうか。今回はBICとBLRT(Bootstrap Likelihood Ratio Test)を利用する。潜在クラス分析はRでもできるが、BLRTはMplusでしかできないので、Mplusで計算する。
データ下記のように出力する。Mplusは変数名はコマンドの中に書き込むので、write.csvで出力する場合は、一行目を消す。write.tableコマンドを使うと変数名は出力されないが、コンマではなくスペース区切りなので、エディタなどで置換をすることになる。
どちらでも手間のかからない方法でやってほしい。変数名を出力しないオプションがあるのかもしれない(いや、きっとあるだろう)が、調べてみてもわからなかったので、今後の課題として積み残しておこうと思う。
write.csv(d3, file = "IPIP-NEO.csv", row.names=FALSE, fileEncoding = "UTF-8")
Mplusの潜在クラスのコマンド(.inpファイル)は下記のように書く。クラス数はc()の中の数字を変えるだけである。クラス数を変える場合はその都度.inpファイルを作り実行する。
TITLE:
Categorical Factor Analysis vs. Latent class Analysis
DATA:
FILE = IPIP-NEO.csv;
VARIABLE:
NAMES = A1-A5 C1-C5 E1-E5 N1-N5 O1-O5;
USEVARIABLES = A1-A5 C1-C5 E1-E5 N1-N5 O1-O5;
CATEGORICAL = A1-A5 C1-C5 E1-E5 N1-N5 O1-O5;
CLASSES = c (2);
ANALYSIS:
TYPE = MIXTURE;
OUTPUT:
TECH14;
BLRTのp-valueは10クラスモデルまで計算してみた。Approximate P-Valueはすべて0.000であり、モデル数を増やせば増やすだけモデルは改善していると判断されている。BICも次第に小さくなっているので、クラスを増やせば増やすほど、モデルは改善している判断されている。このデータは収束しないようだ。残念ながらクラス数の決定はできなかった。理由は後ほど、クラスを詳しく見ていくとわかると思う。
| class |
Approximate P-Value |
BIC |
| 2 |
0.0000 |
64643.860 |
| 3 |
0.0000 |
63269.515 |
| 4 |
0.0000 |
62850.673 |
| 5 |
0.0000 |
62555.632 |
| 6 |
0.0000 |
62486.493 |
| 7 |
0.0000 |
62407.838 |
| 8 |
0.0000 |
62402.985 |
| 9 |
0.0000 |
62397.464 |
| 10 |
0.0000 |
62414.749 |
Rで因子分析
R戻る。
5因子の因子分析をRで行う。
library("psych")
library("GPArotation")
fa5 <- fa(r = d3, nfactors = 5, fm = "minres", rotate = "oblimin", scores=TRUE)
print(fa5, digits = 3)
Rでの潜在クラス分析
潜在クラス分析も5クラスで分析する。BLRTを使わないならば、Rで十分なので、Rで実行する。poLCAパッケージを利用する。注意するのはデータをfactor型にしないとプログラムが走らないことだ。最初にd2でfactor型のデータを作っているので、それを利用する。ちなみに、因子分析はinteger型(整数型)でないとプログラムが走らない。言われてみれば、確かにその通りなのだが、各パッケージはこのあたりは厳格なので、気をつけよう。
library(poLCA)
f <- cbind(A1,A2,A3,A4,A5,C1,C2,C3,C4,C5,E1,E2,E3,E4,E5,
N1,N2,N3,N4,N5,O1,O2,O3,O4,O5)~1
#fomulaの設定。潜在クラス分析に入れる変数を選ぶ
lca5 <- poLCA(f, d2, nclass=5,maxiter=3000, nrep=100) #5クラスモデル
因子分析の結果
因子負荷が0.4以上を太字にした。
| |
因子2
開放性 |
因子1
外向性 |
因子5
協調性 |
因子3
神経症傾向 |
因子4
勤勉性 |
共通性 |
| A1 |
0.196 |
-0.138 |
-0.306 |
0.056 |
-0.080 |
0.115 |
| A2 |
0.002 |
0.033 |
0.511 |
0.041 |
0.061 |
0.272 |
| A3 |
-0.041 |
-0.043 |
0.581 |
0.010 |
0.005 |
0.363 |
| A4 |
-0.089 |
-0.081 |
0.351 |
0.143 |
-0.114 |
0.205 |
| A5 |
-0.097 |
-0.138 |
0.524 |
0.004 |
0.000 |
0.360 |
| C1 |
0.094 |
-0.007 |
0.021 |
0.482 |
0.097 |
0.255 |
| C2 |
0.093 |
0.089 |
0.066 |
0.587 |
0.008 |
0.337 |
| C3 |
0.001 |
0.067 |
0.062 |
0.479 |
-0.012 |
0.230 |
| C4 |
0.131 |
0.030 |
0.098 |
0.512 |
-0.058 |
0.315 |
| C5 |
0.162 |
0.151 |
0.047 |
0.456 |
0.108 |
0.309 |
| E1 |
-0.065 |
0.491 |
-0.057 |
0.081 |
-0.093 |
0.262 |
| E2 |
0.079 |
0.588 |
-0.031 |
0.023 |
-0.051 |
0.408 |
| E3 |
0.099 |
-0.344 |
0.222 |
0.016 |
0.181 |
0.279 |
| E4 |
0.020 |
-0.466 |
0.314 |
0.041 |
-0.087 |
0.412 |
| E5 |
0.132 |
-0.343 |
0.136 |
0.176 |
0.160 |
0.280 |
| N1 |
0.723 |
-0.096 |
-0.083 |
0.009 |
-0.037 |
0.508 |
| N2 |
0.688 |
-0.027 |
-0.077 |
0.007 |
0.020 |
0.472 |
| N3 |
0.618 |
0.111 |
0.069 |
0.004 |
-0.001 |
0.426 |
| N4 |
0.390 |
0.373 |
0.096 |
0.097 |
0.056 |
0.375 |
| N5 |
0.410 |
0.178 |
0.123 |
0.033 |
-0.128 |
0.249 |
| O1 |
0.043 |
-0.095 |
0.086 |
0.064 |
0.353 |
0.179 |
| O2 |
0.134 |
-0.019 |
0.163 |
0.078 |
-0.411 |
0.214 |
| O3 |
0.046 |
-0.132 |
0.128 |
0.036 |
0.429 |
0.268 |
| O4 |
0.077 |
0.220 |
0.132 |
0.041 |
0.201 |
0.093 |
| O5 |
0.104 |
-0.028 |
0.035 |
0.019 |
-0.459 |
0.215 |
順序変数で分析した結果が以前のエントリにあるが、因子負荷が高く、2値に変換して因子分析をると、0.4を切る項目出てきている。
因子分析の因子を作成することには基本的には成功しているが、推定結果は順序変数に劣る。IPIP-NEOのデータでは必ずしも正確に推定が行えたとは言えないだろう。以前のエントリでWISCのデータを用いて連続変数と4値の順序変数、2値のカテゴリカル変数で結果をシミュレーションをしたときには、結果はさほど変わらなかったが、今回は同様の結果を得られなかった。2値のカテゴリカル変数の因子分析は必ずしも、正確に推定できるわけではない、ということに気を付けたほうがよさそうだ。
潜在クラス分析の結果
IPIP-NEOのデータは6件法で測られていて、1が全くあてはまらない(Very Inaccurate)、6が非常にあてはまる(Very Accurate)となっているので、2値にしたときには、2の値の所属確率を見ていくことになる。0.7以上の値に太字をつけている。
| |
class 1 |
class 2 |
class 3 |
class 4 |
class 5 |
質問 |
| 所属確率 |
0.2852 |
0.3343 |
0.1497 |
0.1012 |
0.1297 |
- |
| A1 |
0.2519 |
0.1427 |
0.3085 |
0.1883 |
0.3384 |
他人の気持ちに無関心 |
| A2 |
0.9559 |
0.9499 |
0.7032 |
0.9247 |
0.7001 |
他人の幸福にする方法を知っている |
| A3 |
0.9315 |
0.9471 |
0.5999 |
0.8631 |
0.5546 |
他人をなぐさめる方法を知っている |
| A4 |
0.8544 |
0.9401 |
0.6795 |
0.8119 |
0.5161 |
子供が大すき |
| A5 |
0.8936 |
0.9660 |
0.5906 |
0.9088 |
0.4534 |
人をくつろがせられる |
| C1 |
0.9286 |
0.9196 |
0.7755 |
0.5063 |
0.6187 |
仕事はしっかりとやる |
| C2 |
0.9064 |
0.8984 |
0.7783 |
0.2403 |
0.5972 |
物事は完成するまで続ける |
| C3 |
0.8496 |
0.9020 |
0.7529 |
0.3997 |
0.6019 |
計画通りに行動する |
| C4 |
0.2437 |
0.0636 |
0.2157 |
0.7276 |
0.5158 |
物事を中途半端にする |
| C5 |
0.5258 |
0.2278 |
0.4787 |
0.8958 |
0.8133 |
時間を無駄にする |
| E1 |
0.3153 |
0.2305 |
0.7145 |
0.1693 |
0.7028 |
あまり喋らない |
| E2 |
0.4666 |
0.1616 |
0.7188 |
0.3264 |
0.8919 |
他人へアプローチするのは難しい |
| E4 |
0.8520 |
0.9574 |
0.4195 |
0.9012 |
0.3116 |
簡単に友達を作る |
| E5 |
0.9037 |
0.9222 |
0.5314 |
0.7650 |
0.4304 |
世話をする |
| N1 |
0.7327 |
0.0657 |
0.1143 |
0.3390 |
0.7352 |
怒りやすい |
| N2 |
0.8997 |
0.2199 |
0.2772 |
0.5140 |
0.9345 |
イライラしやすい |
| N3 |
0.8342 |
0.1602 |
0.1695 |
0.3963 |
0.8377 |
気分が頻繁に変動する |
| N4 |
0.6383 |
0.1489 |
0.3663 |
0.4357 |
0.8971 |
しばしば気分がブルーになる |
| N5 |
0.6181 |
0.1655 |
0.2513 |
0.3165 |
0.6686 |
パニックになりやすい |
| O1 |
0.9208 |
0.9526 |
0.7705 |
0.8734 |
0.7389 |
アイデアが多くある |
| O2 |
0.3641 |
0.2229 |
0.2609 |
0.3957 |
0.3985 |
難しい読み物を避ける |
| O3 |
0.8943 |
0.9232 |
0.6494 |
0.8100 |
0.5998 |
会話のレベルを高める |
| O4 |
0.9365 |
0.8641 |
0.8449 |
0.8275 |
0.9333 |
物事を振り返って考える |
| O5 |
0.2271 |
0.1652 |
0.2094 |
0.2399 |
0.3458 |
物事を深くしらべない |
一見して因子分析とは異なる結果になっていることがわかる。
O項目の傾向はどのクラスでもだいたい同じである。
O2「難しい読み物を避ける」とO5「物事を深くしらべない」はどのクラスでも低い。そもそもこれらの項目にYesと言っている人が少ないようだ。アイデアはたくさんあり、会話を面白く高められて、物事を振り返って考えてみるが、難しいものは読まないし、調べ物もしないという傾向がわかる。少し難しい本でも読んで、物事をしっかり調べないと、よいアイデアは出ない気がするし、会話のレベルも高くならない。解釈をすると悪口になってくるので、このあたりでやめておこう。
クラス1
クラス1はだいたいすべての項目で高く出ている。
E項目はE1「あまり喋らない」、E2「他人へアプローチするのは難しい」は低いが、E3「人を魅了する方法を知っている」E4「簡単に友達を作る」E5「世話をする」は高い。典型的なコミュニカティブな人である。N項目はすべて高く「神経症傾向」があることがわかる。
今までの経験では、潜在クラス分析はだいたいの項目があてはまるクラスが1つ作られるパターン、何もあてはまらないクラスが1つ作られるパターンが多かったように思う。個人的に経験した後者のパターンは逸脱・逆境環境系の質問を入れたときである。
簡単にまとめると、誰でも当てはまりそうな項目が多いときはだいたいの項目を満たすクラスが作られ、割と該当者が少ない項目が多いときはすべての項目に宛てはならないクスが作られる傾向があるということだ。もちろん、両方同時に起きることもある。今回は、前者のみ生じている。
クラス2
E項目はクラス1と同じ傾向でコミュニカティブなタイプである。N項目は割合が少なく「神経症傾向」がない。人としては社会に最も適応していそうな人だ。
クラス3
A3「他人をなぐさめる方法を知っている」、A4「子供が大すき」、A5「人をくつろがせられる」がやや低い。E1「あまり喋らない」、E2「他人へアプローチするのは難しい」の割合が高く、E3「人を魅了する方法を知っている」、E4「簡単に友達を作る」、E5「世話をする」の割合が少ない。
まとめると、人付き合いが苦手のようである。これはクラス5と同じ傾向だ。
ただ、N項目の「神経症傾向」の割合が低く、精神的な健康度は高そうである。
クラス4
最も近いのはクラス2である。しかし、C1「仕事はしっかりとやる」、C2「物事は完成するまで続ける」、C3「計画通りに行動する」の割合が低い。仕事や物事をしっかりとしないタイプである。
クラス5
クラス3と同じく人付き合いが苦手である。違いは、N項目の「神経症傾向」の割合が高いという点である。
結論と考察
IPIP-NEOのデータを用いて2値のカテゴリカル因子分析と潜在クラス分析をした結果、両者の結果は大きく異なることが判明した。
変数(概念)を基にしたグループ分けをする因子分析を、ケース(人)を基にしたグループ分けをする潜在クラス分析の特性がかなりよくわかるシミュレーションだったのではないかったかと思う。
心理学のリッカート尺度で計測するデータでは、今回のシミュレーションとよく似た結果、つまり全く結果が異なることが起こるのではないかと思う。因子分析ても潜在クラス分析でもどちらでもよい、とは言いづらいだろう。
データの特性などが変化すると、似たような結果がになる可能性も無くはないだろう。今回はN項目の「神経症傾向」が潜在クラス分析でもわりときれいに区別できていた。疾患を持っている人と、疾患を持っていない人というのは、連続的なのではなく、カテゴリカルに分かれているからであって、不思議はない。
精神医学的なインプリケーションとしては、精神疾患を順序変数で計測する流れへの評価であろうか。推進者が信じるほど利得は統計学的にはない。診断を現在の2値データで行うことに概念的にも、計量的にも問題がないと考えているのは、僕がカテゴリカル変数を扱う社会学出身であるからだけはなく、精神医学で統計の勉強をする人は心理学統計寄りの手技を勉強する傾向にあるため、カテゴリカル変数の扱い方を知らないのだと思う。
心理学的なインプリケーションとしては、リッカート尺度を用いた尺度研究をする際には、因子分析をした方がよく、潜在クラス分析は代替手段にはならないということだろう。
もう少し踏み込んだことをいうと、因子分析のみを行うことに大きな問題があるように思われる。Big5やNEOと呼ばれる研究群は、パーソナリティが5つに分かれるというが、その根拠が全くないことにとりあえず留意すべきである。5つの因子である開放性、外向性、協調性、神経症傾向、勤勉性が研究者の興味関心によって採用されたのだが、その5つに分かれるように質問項目を工夫して洗練させたのであって、そもそも人間のパーソナリティが5つに分かれるわけではない。3つでも6つでも概念を作成して、因子分析を繰り返して、Big3やBig6を作ることも可能である。
IPIP-NEOの25項目バージョンだけで結論を出すのは早計かもしれないが、潜在クラス分析をすると、IPIP-NEOの項目は、神経症傾向以外はバラバラに分類される。そもそも、1~2割くらいの人たちしか「そう思う」と答えていない項目あれば、逆にほとんどの人が「そう思う」と答えている項目もある。
それぞれの因子ごとに潜在クラス分析をしても固まって同じ傾向が出るくらいに質問文を精査した方がよい。因子分析をしてきれいに結果が分かれ、潜在クラス分析をすると、因子単位では少なくとも固まっていて、かつ、各項目が異なったことに関して問うている質問紙がベストである。単発の研究にそのようなことを望むのはやり過ぎだが、NEOの研究規模であれば、そのくらいはやっていて当然のような気がする。