厚生労働省は9日、ひきこもりの人や家族らの支援に役立てるため、初のマニュアルを策定する方針を固めた。長期化、高年齢化が進み、80代の親と50代の子が困窮する「8050問題」が深刻になっている。多様なニーズに対応できるよう自治体の相談窓口などでの活用を想定している。
DFactorモデル[LatentGOLD]
DFactorモデルとは、Discrete Factor Modelsのことで、離散値の探索的因子分析のアプローチの一つである。
世の中では順序や離散データに対して当たり前のようにPearsonの相関係数と最尤法で因子分析している論文ばかりだが、大きな間違いの一つである。
アプローチは3つ考えられる。
1. テトラコリック相関係数を用いた探索的因子分析
テトラコリック相関係数、ポリコリック相関係数用いる因子分析である。ただ、いずれも変数には正規分布を仮定しなければならないという制限がある。順序尺度の場合は正規分布しないことの方が多く、名義尺度の場合は線形ですらないため、正規分布を仮定することはできない。「はい/いいえ」の2択のデータを線形で処理している論文も多いが、明らかな間違いである。
また、推定法として最尤法がよく使われるが、最尤法は連続変数で、変数が正規分布していることを前提としているので、こちらの点でも使いづらい。
2. Muthén(1978)のアプローチ
こちらはMplusに実装されている。
- Muthén, B. (1978). Contributions to factor analysis of dichotomous variables. Psychometrika, 43(4), 551–560. https://doi.org/10.1007/BF02293813
理屈では可能なのだが、実際に分析してみると、うまくいった試しがない。うまくいった人もいるのだろうが、個人的には失敗続きである。 こういったことから必要となってくるのが、3つ目の候補であるVermuntらの開発したDFactorモデルである。
離散因子(discrete factor models: DFactor)モデル
従来の因子分析(FA)では、連続的な観測変数は、1つまたは複数の連続的な潜在因子(CFactor)の線形関数として表現される。DFactor分析は,いくつかの点でFAとは異なる。
観測変数は、名目、順序、連続、計数を含む混合尺度タイプが可能である。潜在変数は、連続ではなく、2つ以上の順序づけられたカテゴリ(レベル)を含む離散である。解を解釈可能にするために回転させる必要がない(「回転」の不確定性の問題は、線形モデルに特有のものである。)
さらに、DFactorのクロス集計により、クラスターのセットが定義される。例えば、2つの二項対立のDFactorVとWは,4つの潜在クラス(4つのクラスター)を生み出す。
| W=1 | W=2 | |
|---|---|---|
| V=1 | X = 1 | X = 2 |
| V=2 | X = 3 | X = 4 |
実行
"gss82white.sav"を開く。このデータはLatentGoldのサンプルデータである。RのpoLCAパッケージにあるgss82とも同じデータである。
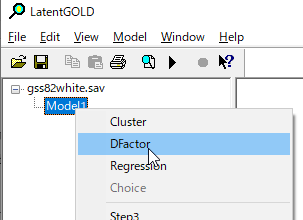
DFactorを選択。
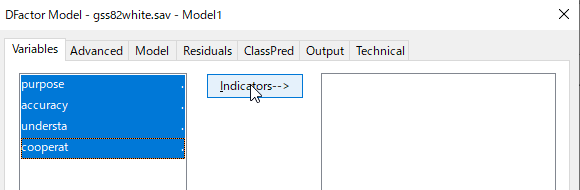
変数を選択肢、Indicatorを押して分析に組み入れる。
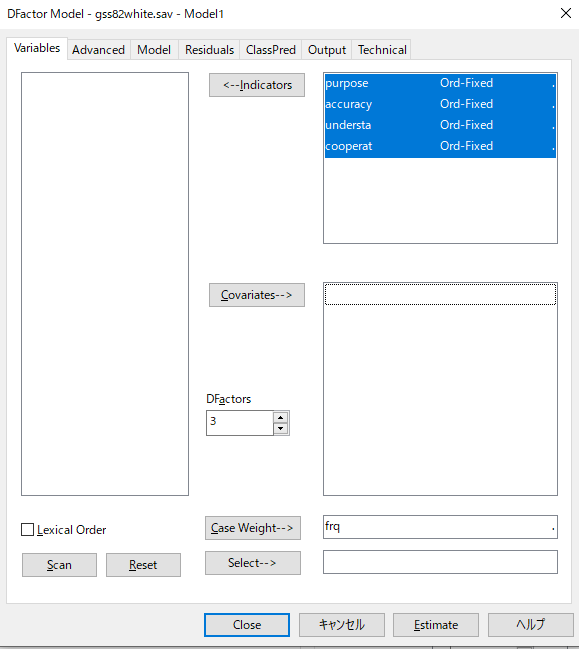
尺度レベルの決定
投入した変数の種類を設定する。
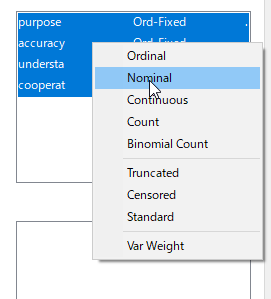
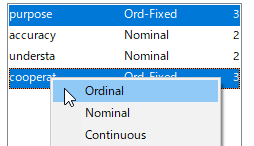
[Nominal]もしくは[Ordinal]を指定する。まずは[Nominal]でやってみよう。
なお、このデータはスタック形式なので、[Case weight]に頻度を入れる。このデータでは頻度が"frq"と名付けられているため、自動的に入るようになっている。
![]()
今回は3因子モデルを実施してみる。
[Estimate]をクリック
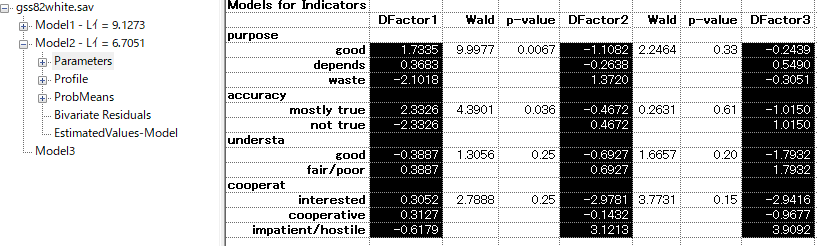
"Parameter"の各Factorの数値をみると、徐々に数値が増加しているパターンのところは順序での推定が良いと考えられる。また、もともと質問文も回答が3値のものは順序として設計されているため、順序での推定の方がよいだろう。
今推定しているモデル図ではModel2をクリックして条件を変えるだけでよい。
因子数の決定
はじめに3因子モデルの推定をやってみたが、他のモデルの推定もしてみよう。
今推定しているモデルをダブルクリックして、Dfactorsを4にして[Estimate]

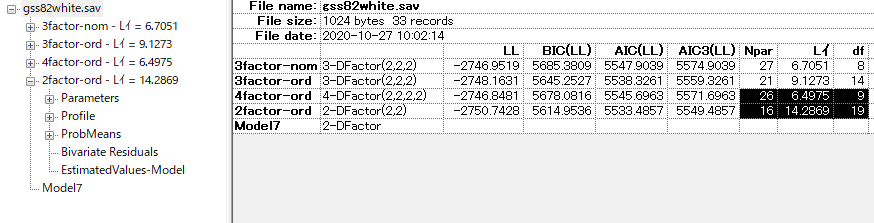
この画面で書くモデルのAICとBICを比較できる。 DFactorモデルではAICとBICのどちらを優先すれば良いかはよくわからない。潜在クラス分析では一般的にBICを優先することがモンテカルロシミュレーションで示唆されているものの、データの分布次第で変わるため、BICがよいと一概にも言えない。DFactorモデルではおそらく論文が書かれていないはずである。
次に2因子モデルも検討してみよう。
BLRT: Bootstrap Likelihood Ratio Test
特定の分布に依存しない条件付きブートストラップを利用する方法。今回は2因子と3因子を比較するので、3因子モデルで右クリックをして、[Bootstrap -2LL Diff]をクリック

2因子モデルと比較をする。
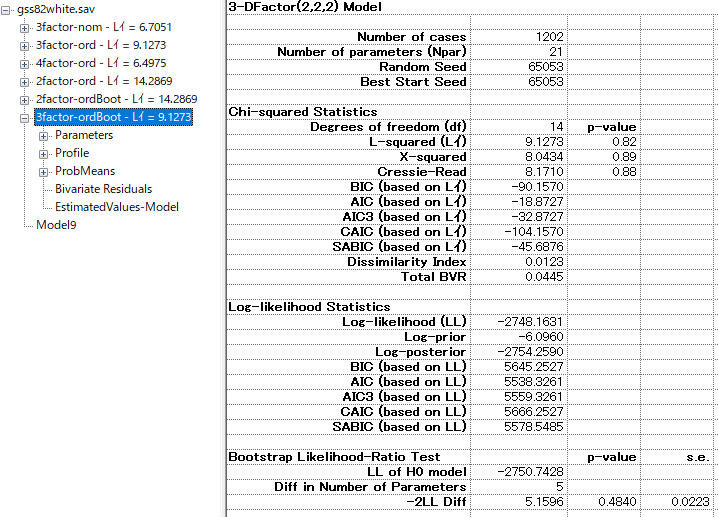
p-valueが5%以下である場合、2因子→3因子でモデルは改善されていると判断できる。この場合は、0.484であるため、2因子モデルが適切ということになる。
VLMR: Vuong-Lo-Mendell-Rubin LIikelihood Ratio Test
[Vuong -2LL Diff]を選択すれはVLMRが可能である。
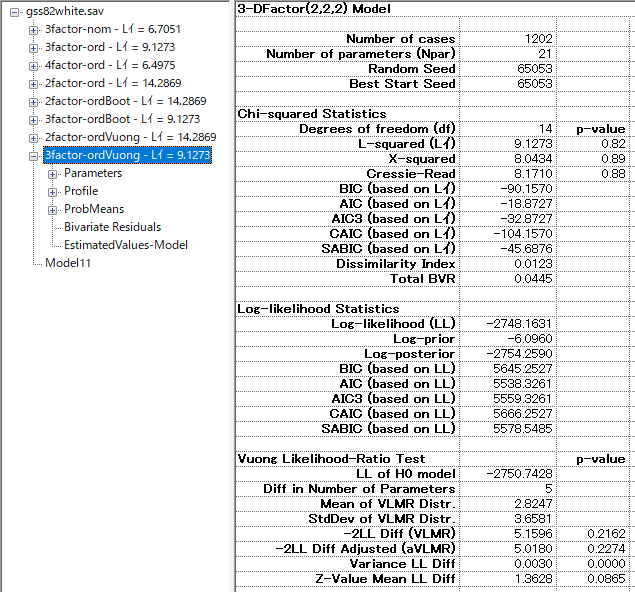
数値は-2LL Diff(VLMR)のところの0.2162か、adjustedの0.2274のどちらかを採用する。どちらがいいのかは情報がないのでよくわからない。おそらくVLMRのところで問題ないだろう。
VLMRでも2因子→3因子でモデル改善はしていないという判断がされた。
因子負荷量
2因子モデルがよいということが分かったので、2因子モデルの因子負荷量をみよう。
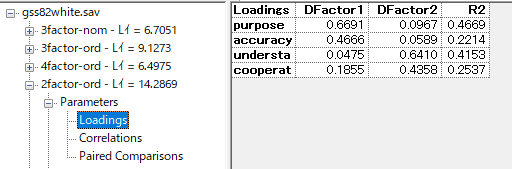
通常の探索的因子分析と同じく、名前をつけるという手順に入る。
文献
Vermunt, J.K., and Magidson, J. (2004). Factor analysis with categorical indicators: a comparison between traditional and latent class approaches. In: Van der Ark, A., Croon, M.A., and Sijtsma, K. (Eds), New Developments in Categorical Data Analysis for the Social and Behavioral Sciences. Erlbaum.
https://www.statisticalinnovations.com/wp-content/uploads/Vermunt2004.pdf
Magidson, J., and Vermunt, J.K. (2003). Comparing latent class factor analysis with traditional factor analysis for datamining. In: Bozdogan, H. (Ed), Statistical Datamining & Knowledge Discovery, Chapter 22, 373-383. Boca Raton: Chapman & Hall/CRC. CRC Press.
https://www.statisticalinnovations.com/wp-content/uploads/Magidson2003.pdf
Magidson, J., and Vermunt, J.K. (2001). Latent class factor and cluster models, bi-plots and related graphical displays. Sociological Methodology, 31, 223-264.
https://www.statisticalinnovations.com/wp-content/uploads/Magidson2001.pdf
高齢者にも激増 危険なスマホ依存症 SNSが高齢者のキレやすさを助長?(夕刊フジ)
「いわゆる「スマホ依存症」ですが、現在は若者より高齢者のほうが多いです。若者の場合、「ゲーム依存症」が中心」(吉竹弘行)https://t.co/6G7QPjdXsC
— 井出草平 Sohei IDE (@Sohei_IDE) 2023年5月9日
高齢者の方が多いなんて文献は見たことがないし、そもそもスマホ依存症は精神疾患として認められていない。
「脳科学的に言えば、〝いいね〟はドーパミンを大量に分泌させます。また、前頭葉の機能を低下させ、感情のコントロールが利かなくなります。」
— 井出草平 Sohei IDE (@Sohei_IDE) 2023年5月9日
脳内のドーパミン計測には[11C]RACを用いたPET検査をするが、Twitter利用で計測された研究はないはず。根拠はどこに?
「日本ほどツイッターが流行っている国はありません」「140字の文字制限が日本人の思考、知能程度に適しているからとも言われます。それ以上だと理解できないというのです。」
— 井出草平 Sohei IDE (@Sohei_IDE) 2023年5月9日
この人、日本人はバカだと堂々と言っている。
「脳科学的に言えば、〝いいね〟はドーパミンを大量に分泌させます。また、前頭葉の機能を低下させ、感情のコントロールが利かなくなります。」
— 井出草平 Sohei IDE (@Sohei_IDE) 2023年5月9日
脳内のドーパミン計測には[11C]RACを用いたPET検査をするが、Twitter利用で計測された研究はないはず。根拠はどこに?
ドーパミンが前頭葉の機能を低下させるという珍説を唱えている。ここまで間違っているものは、訂正のしようがない。哺乳類はごはんを食べるとドーパミンが50%増えるので、ごはんを食べるたびに前頭葉に大ダメージが与えられていることになる。
— 井出草平 Sohei IDE (@Sohei_IDE) 2023年5月9日
吉竹弘行(よしたけ・ひろゆき) 1995年、藤田保健衛生大学(現・藤田医科大学)卒業後、浜松医科大学精神科などを経て、明陵クリニック院長(神奈川県大和市)。著書に『「うつ」と平常の境目』(青春新書)。
")
また青春出版か。
”被害女性”はすでに亡くなり…18年前に全国的な話題になった”騒音おばさん”のいま(Friday)
事件当初、Aさんを一方的に責める声が相次いだが、裁判の過程でAさんが難病の家族を抱えて心身ともに疲弊していたことも明らかになった。事情を知る住民のなかには同情する声もあったという。
妄想性障害でしょうか。
全ての組み合わせでCramerのVを計算する、1つのデータフレームで実行する場合
先に作成したコードの変型版。
コード
# ライブラリの読み込み
library(dplyr)
# ダミーデータの作成
set.seed(42)
dummy_data <- data.frame(matrix(sample(0:2, 1000, replace = TRUE), ncol = 10))
colnames(dummy_data) <- paste0("var", 1:10)
# Cramer's V関数の定義
cramers_v <- function(x, y) {
contingency_table <- table(x, y)
chi2 <- chisq.test(contingency_table)
n <- sum(contingency_table)
k <- min(nrow(contingency_table), ncol(contingency_table))
cramers_v <- sqrt(chi2$statistic / (n * (k - 1)))
return(list("Cramers_V" = cramers_v, "Chi_square" = chi2$statistic, "P_value" = chi2$p.value))
}
# 解析
combinations <- combn(ncol(dummy_data), 2)
result <- data.frame()
for (i in 1:ncol(combinations)) {
x <- dummy_data[[combinations[1, i]]]
y <- dummy_data[[combinations[2, i]]]
analysis_result <- cramers_v(x, y)
result <- rbind(result, c(combinations[, i], unlist(analysis_result)))
}
colnames(result) <- c("Var1", "Var2", "Cramers_V", "Chi_square", "P_value")
# CSVファイルへの書き出し
write.csv(result, "cramers_v_results.csv", row.names = FALSE)
確認
ちゃんと計算したかは、確認はvcdパッケージで確かめられる。
library(vcd) tab <- table(dummy_data$var1, dummy_data$var2) summary(assocstats(tab))
プロンプト
今回はchatGPT4.0で実行した。コードを書く力もPhindよりもchatGPT4.0の方が明らかに上だと思う。
Rのコードを作成してください。 まず、下記のダミーデータを作成してください。順序尺度の変数が10個含まれたデータフレームがあります。それぞれの変数は0から2までの値を取ります。 次に関数を作成します。 Cramer's Vの関数をパッケージを使わずに作ってください。 次に解析を行います。ダミーデータの中から2つの変数を選び、先ほど作成した関数を用いてCramer'sを計算します。すべての組み合わせで行ってください。出力としてCramer's、カイ二乗値、P値を示し、csvファイルとして書き出してください。
無条件平均値代入法 Unconditional Mean Imputation [stata]
欠測値の補足方法の一つ。やっていることは変数の平均値を出し、欠損値の中に入れる、というだけである。
利点については以下のようなものが挙げられている。
- 簡単で直感的: 平均値代入法は非常に簡単で直感的な手法であるため、理解しやすく、実装も容易である。欠損値を変数の平均値で置き換えるだけで補完ができるため、手軽にデータの欠損を処理することができる。
- 計算負荷が低い: 平均値代入法は計算負荷が低く、大規模なデータセットに対しても迅速に適用できる。より高度な補完手法に比べて、計算時間やリソースが節約できる場合がある。
- 欠損値の影響を軽減: 欠損データが完全にランダムに発生している場合、平均値代入法は全体の傾向を維持することができるため、欠損値の影響をある程度軽減できる。
欠点について以下のようなものが挙げられている。
- 分散の低下: 平均値代入法では、すべての欠損値が同じ平均値で置き換えられる。そのため、データの分散が低下し、結果として、データの構造や相関関係が歪められることがある。
- 推定値のバイアス: 欠損が完全にランダムでない場合、平均値代入法によって得られた推定値にバイアスが生じることがある。例えば、欠損が特定の値に偏っている場合、平均値代入法ではその偏りが適切に反映されないため、誤った結果を導く可能性がある。
- 欠損データのパターンの無視: 平均値代入法は、欠損データのパターンや潜在的な関係を考慮しない。これは、欠損が特定の変数や状況に関連して発生している場合、その情報が失われることを意味する。
- 一貫性の欠如: 平均値代入法では、欠損値がある変数の平均値が使用されるため、データセット内の他の変数との関係が一貫しなくなることがある。
これらの特性を利用して、使うことが必要である。
statコード
データ読み込み
use https://stats.idre.ucla.edu/wp-content/uploads/2017/05/hsb2_mar.dta, clear
まず、欠損値を持つ変数の平均値を計算し、平均値を用いて欠損値を補完する。
以下のコードではwrite_mean、read_mean、math_meanの変数にそれぞれの平均値が格納され、write_imputed、read_imputed、math_imputedに平均値代入法により補完された変数が格納される。
egen write_mean = mean(write) egen read_mean = mean(read) egen math_mean = mean(math) gen write_imputed = write replace write_imputed = write_mean if write_imputed == . gen read_imputed = read replace read_imputed = read_mean if read_imputed == . gen math_imputed = math replace math_imputed = math_mean if math_imputed == .
平均値代入前の変数間の平均値および相関関係
sum write read math , sep (6)
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
write | 183 52.95082 9.257773 31 67
read | 191 52.28796 10.21072 28 76
math | 185 52.8973 9.360837 33 75
相関。
corr write read math
(obs=161)
| write read math
-------------+---------------------------
write | 1.0000
read | 0.5923 1.0000
math | 0.6203 0.6474 1.0000
平均値代入後の変数間の平均値および相関関係
sum write_imputed read_imputed math_imputed
Variable | Obs Mean Std. dev. Min Max -------------+--------------------------------------------------------- write_impu~d | 200 52.95082 8.853514 31 67 read_imputed | 200 52.28796 9.97715 28 76 math_imputed | 200 52.8973 9.00113 33 75
相関
corr write_imputed read_imputed math_imputed
| write_~d read_i~d math_i~d
-------------+---------------------------
write_impu~d | 1.0000
read_imputed | 0.5480 1.0000
math_imputed | 0.5491 0.6159 1.0000
平均にほとんど変化がない。しかし、欠損情報を持つ観測値の平均値を代入した後、標準偏差が明らかに低くなっている。これは、平均値で全員を代入すると、変数の変動が減るからだ。 さらに、相関係数の表から、各変数(write、read、math)間の相関減衰していることが分かる。したがって、これらの変数間の関連を推定しようとする回帰モデルも、その効果が弱くなる。