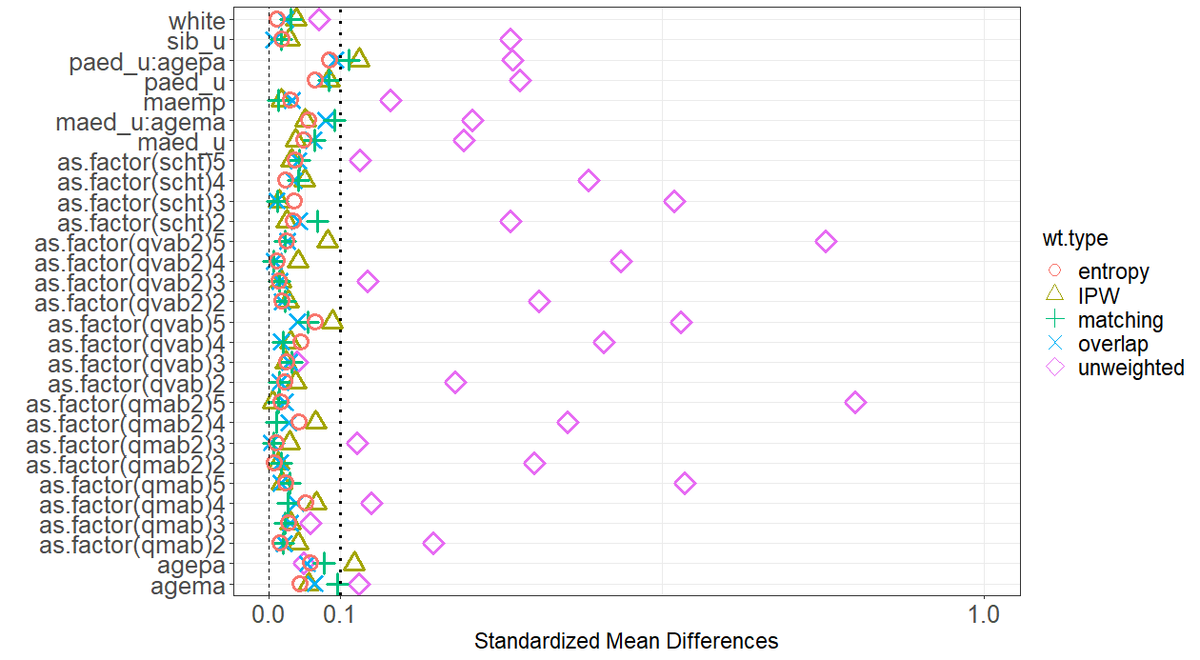
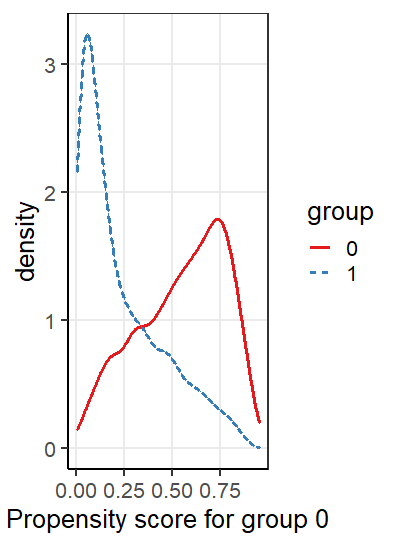
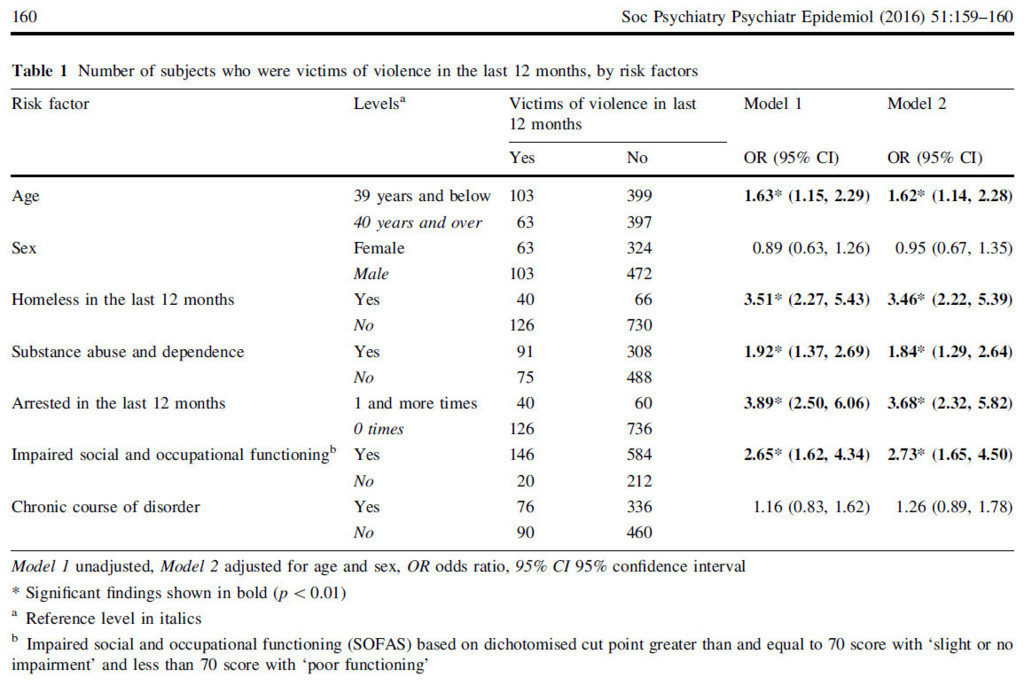
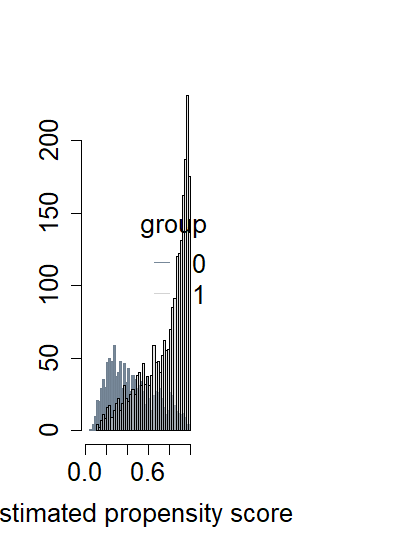処置効果推定量とは、観察データに基づき、ある処置が結果に及ぼす因果的な効果を推定するものである。
本日の投稿では、4つの処置効果推定量について説明する。
- RA: 回帰調整 Regression adjustment
- IPW: 逆確率重み付け Inverse probability weighting
- IPWRA: 逆確率重み付けと回帰調整 Inverse probability weighting with regression adjustment
- AIPW: 拡張逆確率重み付け Augmented inverse probability weighting
マッチング推定量については、後編に譲る。
処置効果推定量には、魔法のように因果関係を抽出するものはないことに注意しなければならない。観察データの回帰分析同様、因果関係の解釈は、合理的な科学的根拠に基づいて行われなければならない。
はじめに
ここでは、処置と結果について説明する。
処置とは新薬のことであり、その結果は血圧やコレステロールの値である。処置とは、外科的処置であり、その結果は患者の患者の可動性である。処置とは、職業訓練プログラムであり、その成果は雇用や賃金であるかもしれない。処置とは、ある製品の売り上げを伸ばすための広告キャンペーンである可能性もある。
母親の喫煙が出産時の赤ちゃんの体重に影響を与えるかどうかを考えてみよう。このような質問には、観察データを用いてのみ答えることができる。実験では倫理的に問題がある。
観察データの問題点は、被験者が治療を受けるかどうかを選択することである。例えば、ある母親がタバコを吸うか吸わないかを決める。被験者は、処置群と非処置群に自己選択したと言われている。
理想的な世界では、因果関係や治療と結果の関係を検証するために実験を計画します。被験者を治療群と非治療群に無作為に割り当てる。治療法を無作為に割り当てることで、治療と結果の独立性が保証され、分析が非常に簡単になる。
因果推論には、各治療水準でのアウトカムの無条件平均の推定が必要である。我々は、データが観察的か実験的かにかかわらず、治療を受けたという条件付きで各被験者の結果を観察するだけである。実験データでは、治療の無作為割付により、治療が結果に独立であることが保証されているので、観察された治療に対する結果の平均が、関心のある無条件平均を推定する。観察データでは、治療の割り当てプロセスをモデル化する。もし我々のモデルが正しければ,治療割り当てプロセスは,我々のモデル中の共変量に条件づけられたランダムと同じとみなされる.
例を考えてみよう。図1は、Cattaneo (2010)が用いたものと同様の観測データの散布図だ。治療変数は、母親の妊娠中の喫煙状況で、結果は、赤ちゃんの出生体重である。
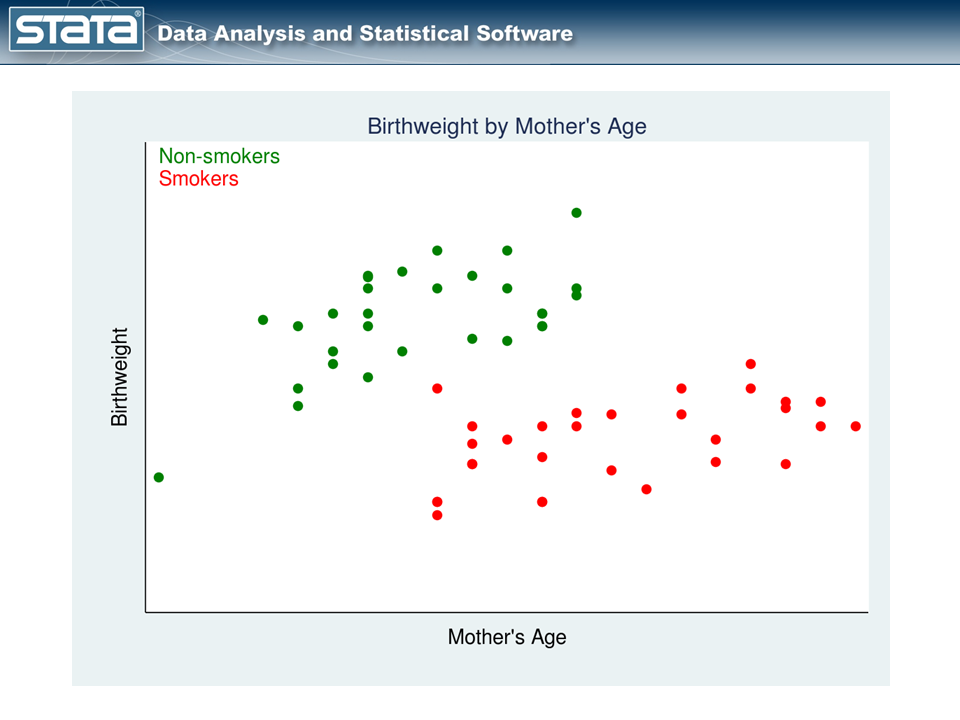
赤い点は妊娠中にタバコを吸った母親、緑の点は吸わなかった母親を表している。喫煙するかどうかは母親自身が選択したことであり、そのことが分析を複雑にしている。
喫煙した母親としなかった母親の赤ちゃんの平均出生時体重を比較することで、喫煙が出生時体重に及ぼす影響を推定することはできない。なぜだろう?もう一度、グラフを見てみてほしい。喫煙の有無にかかわらず、高齢の母親ほど出生児が重い傾向がある。このデータでは、母親の年齢が高いほど喫煙者である可能性も高い。このように、母親の年齢は治療状況と結果の両方に関係している。では、どうすればいいのだろうか?
RA: 回帰調整推定量 The regression adjustment estimator
回帰調整推定量(RA)は、非ランダムな治療割り付けを考慮するために結果をモデル化する。
私たちは、"喫煙する母親が喫煙しないことを選択していたら、結果はどのように変化しただろうか?" または "喫煙しない母親が喫煙することを選択していたら、結果はどのように変化しただろうか? "と尋ねるかもしれない。もし、これらの反実仮想的な質問に対する答えがわかれば、分析は簡単だ。反実仮想的な結果から観測結果を差し引くだけでいい。
反実仮想的な結果は、治療効果に関する文献では、観察されない潜在的な結果 unobserved potential outcomesと呼ばれている。unobservedという単語は省略されることもある。
我々は、これらの未観測の潜在的な結果の測定値を構築することができ、データは次のようになる。
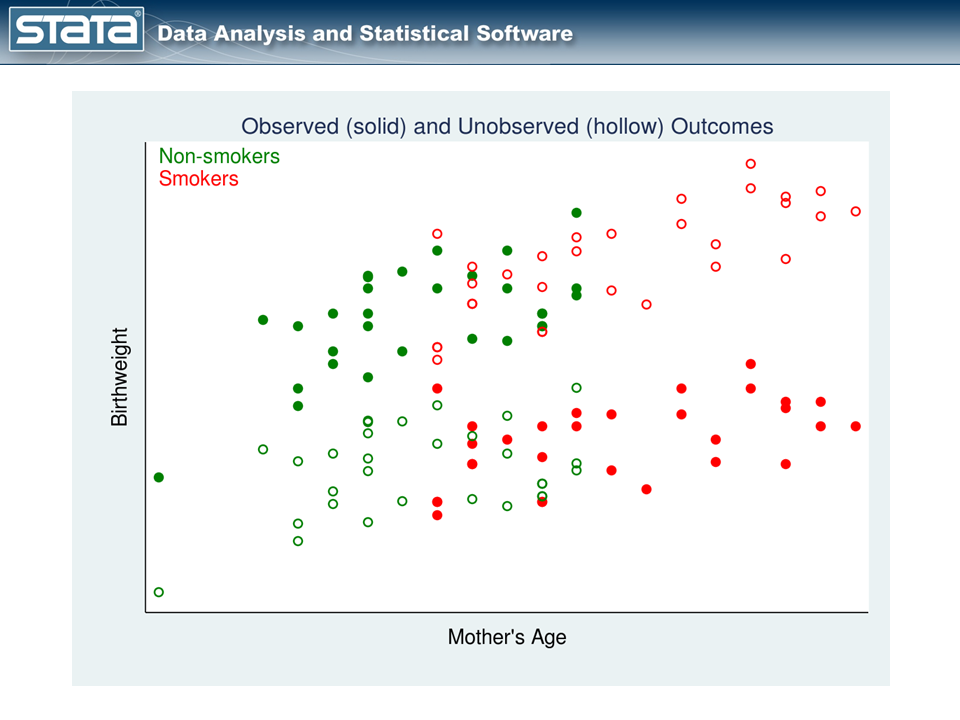
図2では、観測されたデータを実線で、観測されなかった潜在的な結果を空洞の点で示している。赤い点は、喫煙者がタバコを吸わなかったらどうなるかを示している。緑の点は、非喫煙者が喫煙していた場合の潜在的な結果を示している。
そして、観察されたデータ(実線)を使って、2つの治療群に別々の線形回帰モデルをあてはめることで、観察されない潜在的な結果を推定することができる。
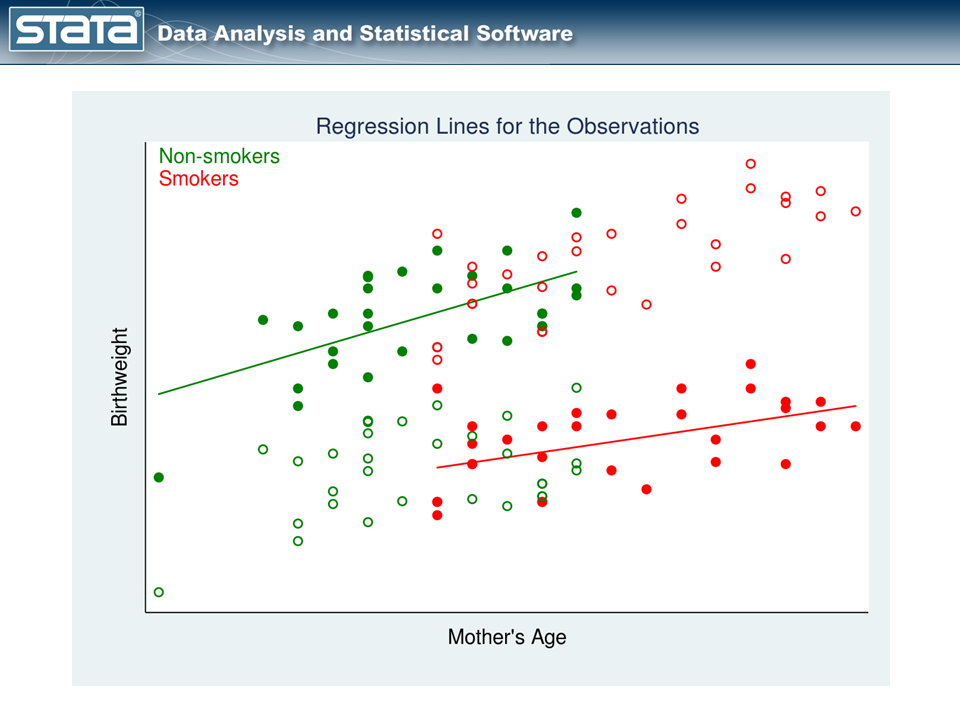
図3では、非喫煙者の回帰線(緑の線)と喫煙者の回帰線(赤の線)を示している。
この2本の線が何を意味しているのかを理解しよう。
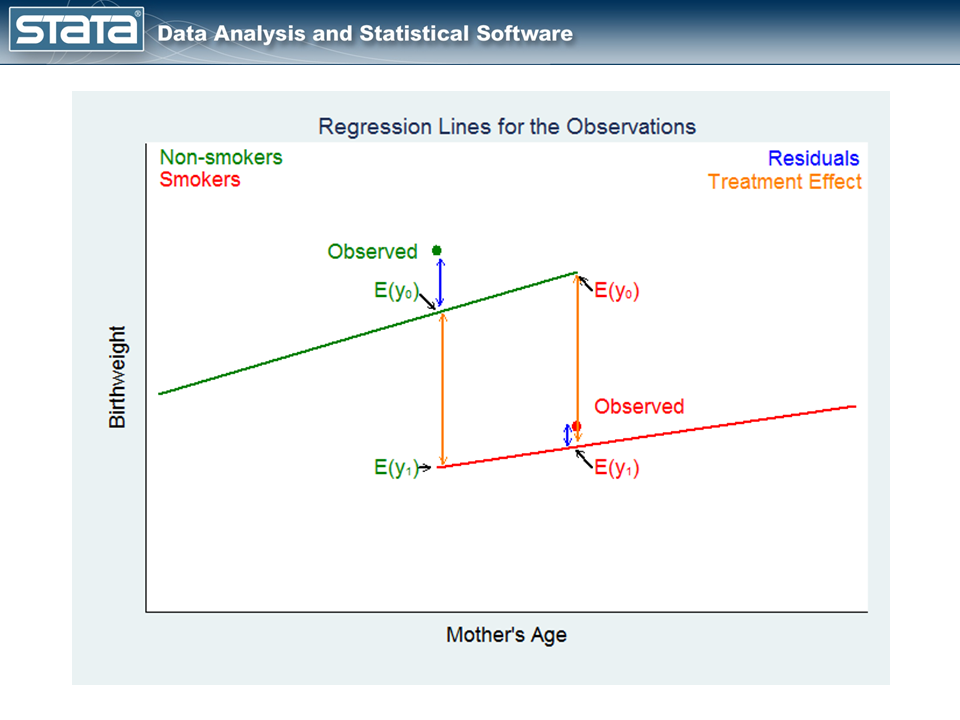
図4の左側の緑色の点、Observedと書かれているのは、タバコを吸わない母親の観測値だ。緑の回帰線上のE(y0)と書かれた点は、母親の年齢とタバコを吸わなかったと仮定した場合の赤ちゃんの予想出生体重である。赤の回帰線上のE(y1)という点は、同じ母親が喫煙していた場合の赤ちゃんの出生体重の期待値である。
これらの期待値の差が、治療を受けなかった人たちの共変量特異的治療効果を推定する。
さて、もう一つの反実仮想の問題を見てみよう。
図4の右側の赤い点、Observedと書かれているのは、妊娠中にタバコを吸った母親の観測値です。緑と赤の回帰線上の点は、2つの治療条件下での母親の赤ちゃんの予想出生体重(潜在的な結果)を再び表す。
これらの期待値の差は、治療を受けた人の共変量特異的な治療効果を推定する。
我々は,各被験者について,共変量値に条件付けられた平均治療効果(ATE)を推定することに注意されたい.さらに、この効果は、実際にどの治療を受けたかに関係なく、各被験者について推定する。データ中のすべての被験者に対するこれらの効果の平均が、ATEを推定する。
我々は、図4を使って、受けた治療に関係なく、各被験者が各治療水準で得るであろう結果の予測を動機づけることもできる。この話は、上記の話と類似している。データ中のすべての被験者に対するこれらの予測の平均は、各治療水準に対する潜在的な結果の平均(POMs)を推定する。
推定されたPOMsの差が、上述のATEと同じ推定値であることは、心強いことである。
治療された人のATE(ATET)は、ATEと似ているが、治療群で観測された被験者だけを使用するものである。この治療効果の計算方法は、回帰調整(RA)と呼ばれている。
データセットを開いて、Stataを使って試してみよう。
. webuse cattaneo2.dta, clear . teffects ra (bweight mage) (mbsmoke), pomeans
我々は、最初の括弧の中に、結果変数とその共変量で結果モデルを指定する。この例では、結果変数は bweight で、唯一の共変量は mage です。
コマンド
- ra: Regression adjustment
- pomeans: estimate potential-outcome means
変数
- bweight: Infant birthweight (grams)
- mage: Mother's age
- mbsmoke: 1 if mother smoked
我々は、2番目の括弧の中で、治療モデル(単に治療変数)を指定する。この例では、治療変数 mbsmoke だけを指定する。共変量については、次のセクションで説明する。
このコマンドを入力した結果は以下のとおり。
Iteration 0: EE criterion = 7.878e-24
Iteration 1: EE criterion = 8.468e-26
Treatment-effects estimation Number of obs = 4642
Estimator : regression adjustment
Outcome model : linear
Treatment model: none
------------------------------------------------------------------------------
| Robust
bweight | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
POmeans |
mbsmoke |
nonsmoker | 3409.435 9.294101 366.84 0.000 3391.219 3427.651
smoker | 3132.374 20.61936 151.91 0.000 3091.961 3172.787
------------------------------------------------------------------------------
出力は、すべての母親が喫煙した場合の平均出生体重は3,132g、母親が喫煙しなかった場合の平均出生体重は3,409gとなることを報告する。
POMを差し引くことで、出生体重に対する喫煙のATEを推定することができる。3132.374 - 3409.435 = -277.061. また、teffects raコマンドにateオプションを付けて再実行すれば、標準誤差と信頼区間を得ることができる。
ate: estimate average treatment effect in population; the default
. teffects ra (bweight mage) (mbsmoke), ate
Iteration 0: EE criterion = 7.878e-24
Iteration 1: EE criterion = 5.185e-26
Treatment-effects estimation Number of obs = 4,642
Estimator : regression adjustment
Outcome model : linear
Treatment model: none
----------------------------------------------------------------------------------------
| Robust
bweight | Coefficient std. err. z P>|z| [95% conf. interval]
-----------------------+----------------------------------------------------------------
ATE |
mbsmoke |
(Smoker vs Nonsmoker) | -277.0611 22.62844 -12.24 0.000 -321.4121 -232.7102
-----------------------+----------------------------------------------------------------
POmean |
mbsmoke |
Nonsmoker | 3409.435 9.294101 366.84 0.000 3391.219 3427.651
----------------------------------------------------------------------------------------
出力は、我々が手作業で計算したのと同じ、-277.061のATEを報告している。ATEは、各母親が喫煙した場合の出生時体重と、喫煙しない場合の出生時体重の差の平均値である。
ATETはteffects raコマンドでatetオプションをつけて推定することもできるが、ここでは省略する。
atet: estimate average treatment effect on the treated
IPW: 逆確率重み付け Inverse probability weighting
RA 推定法は、非ランダムな治療割り付けを説明するために結果をモデル化する。研究者の中には、処置の割り当てプロセスをモデル化し、結果のモデルを指定しないことを好む人もいます。
私たちのデータでは、喫煙者は非喫煙者よりも高齢である傾向があることが分かっている。また、母親の年齢が出生体重に直接影響するという仮説もある。このことは、図1で観察さ れたが、以下にもう一度示す。
この図から、処理割り当てが母親の年齢に依存していることがわかる。この依存性を調整する方法が欲しいところである。特に、高年齢の緑色と低年齢の赤色のポイントがもっとあればいいと思われる。そうすれば、各群の平均出生時体重は変化するはずだ。それが平均値の差にどのように影響するかはわからないが、差の推定値がより良くなることはわかる。
同様の結果を得るために、低年齢層の喫煙者と高年齢層の非喫煙者のウェイトを高くし、高年齢層の喫煙者と低年齢層の非喫煙者のウェイトを低くするつもりである。
我々は、次のような形式のプロビットまたはロジット・モデルを当てはめる。
Pr(woman smokes) = F(a + b*age)
teffectsは、デフォルトでlogitを使用しますが、ここでは、説明のためにprobitオプションを指定する。
そのモデルを適合させると、データ中の各オブザベーションの予測値 Pr(woman smokes) を得ることができる。これを pi と呼ぶことにする。そして、我々のPOM計算(これは単なる平均計算である)を行う際に、我々は観察結果を重みづけするために、これらの確率を使用する。喫煙者である確率が小さいときに重みが大きくなるように、喫煙者のオブザベーションを1/piで重みづけする。非喫煙者である確率が小さいときに重みが大きくなるように、非喫煙者のオブザベーションを1/(1-pi) で重みづけする。
その結果、図1に代わって次のようなグラフになる。
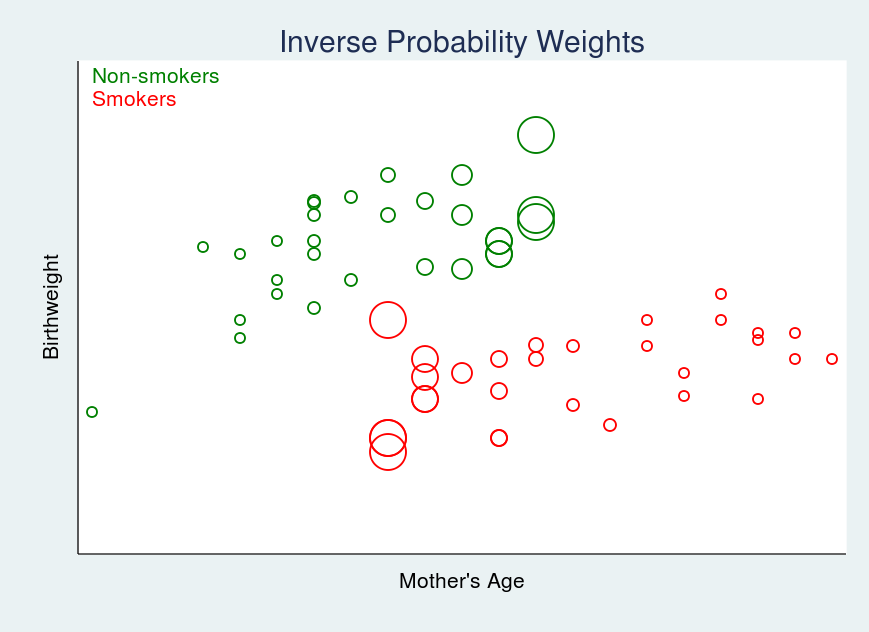
図5では、大きな円は大きな重みを示している。
このIPW推定量を用いてPOMを推定するには、以下のように入力する。
. teffects ipw (bweight) (mbsmoke mage, probit), pomeans
最初の括弧の組は、結果モデルを指定する。これは、この場合、単に結果変数であり、共変量はない。2番目の括弧の組は、処置モデルで、結果変数(mbsmoke)、共変量(この場合、mageだけ)、モデルの種類(probit)が続くものを指定する。
. teffects ipw (bweight) (mbsmoke mage, probit), pomeans
Iteration 0: EE criterion = 1.007e-21
Iteration 1: EE criterion = 1.413e-26
Treatment-effects estimation Number of obs = 4,642
Estimator : inverse-probability weights
Outcome model : weighted mean
Treatment model: probit
------------------------------------------------------------------------------
| Robust
bweight | Coefficient std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
POmeans |
mbsmoke |
Nonsmoker | 3408.979 9.307838 366.25 0.000 3390.736 3427.222
Smoker | 3133.479 20.66762 151.61 0.000 3092.971 3173.986
------------------------------------------------------------------------------
出力結果は、全ての母親が喫煙した場合の平均出生体重は3,133g、母親が誰も喫煙しなかった場合の平均出生体重は3,409gとなることが報告された。
このとき、ATEは-275.5であり、仮に下記のように記した場合、
. teffects ipw (bweight) (mbsmoke mage, probit), ate
Iteration 0: EE criterion = 2.280e-25
Iteration 1: EE criterion = 1.413e-26
Treatment-effects estimation Number of obs = 4,642
Estimator : inverse-probability weights
Outcome model : weighted mean
Treatment model: probit
----------------------------------------------------------------------------------------
| Robust
bweight | Coefficient std. err. z P>|z| [95% conf. interval]
-----------------------+----------------------------------------------------------------
ATE |
mbsmoke |
(Smoker vs Nonsmoker) | -275.5007 22.67711 -12.15 0.000 -319.947 -231.0544
-----------------------+----------------------------------------------------------------
POmean |
mbsmoke |
Nonsmoker | 3408.979 9.307838 366.25 0.000 3390.736 3427.222
----------------------------------------------------------------------------------------
標準誤差は22.68、95%信頼区間は [-319.9,231.0] であることを知ることができる。
teffects raと同様に、ATETを求める場合は、teffects ipwコマンドにatetオプションを付けて指定すればいい。
IPWRA: 逆確率重み付けと回帰調整 Inverse probability weighting with regression adjustment
RA推定量は、非ランダムな治療割り付けを考慮した結果をモデル化する。IPW 推定法は、非ランダムな処理割り当てを考慮するために、処理をモデル化するものである。IPWRA推定量では、非ランダムな治療割り付けを考慮するために、結果と処置の両方をモデル化します。
IPWRAは、IPW重みを使用して、その後回帰調整を行うために使用される修正回帰係数を推定する。
結果モデルと処置モデルの共変量は同じである必要はなく、被験者の処置グループの選択に影響する変数が結果に関連する変数と異なることが多いので、そうでないことがよくある。IPWRA推定量にはダブルロバスト特性があり、これは治療モデルまたは結果モデルのどちらか一方(両方ではない)が誤って規定されても、効果の推定値が一致することを意味する。
低出生体重児のデータを使って、より複雑なアウトカムと治療モデルを考えてみよう。
アウトカムモデルには、
- 1.mage: 母親の年齢
- 2.prenatal1: 最初の妊娠期間中の出産前訪問を表す指標
- 3.mmarried: 母親の婚姻状況を表す指標
- 4.fbaby:第一子であることを表す指標
処置モデルには
- 1.結果モデルのすべての共変量
- 2.mage2
- 3.medu: 母親の教育年数
また、結果モデルと処置モデルの係数を報告するために、aequationsオプションを指定する。
aequations: display auxiliary-equation results
. teffects ipwra (bweight mage prenatal1 mmarried fbaby) ///
> (mbsmoke mmarried c.mage##c.mage fbaby medu, probit) ///
> , pomeans aequations
Iteration 0: EE criterion = 9.372e-21
Iteration 1: EE criterion = 5.435e-26
Treatment-effects estimation Number of obs = 4,642
Estimator : IPW regression adjustment
Outcome model : linear
Treatment model: probit
-------------------------------------------------------------------------------
| Robust
bweight | Coefficient std. err. z P>|z| [95% conf. interval]
--------------+----------------------------------------------------------------
POmeans |
mbsmoke |
Nonsmoker | 3403.336 9.57126 355.58 0.000 3384.576 3422.095
Smoker | 3173.369 24.86997 127.60 0.000 3124.624 3222.113
--------------+----------------------------------------------------------------
OME0 |
mage | 2.893051 2.134788 1.36 0.175 -1.291056 7.077158
prenatal1 | 67.98549 28.78428 2.36 0.018 11.56933 124.4017
mmarried | 155.5893 26.46903 5.88 0.000 103.711 207.4677
fbaby | -71.9215 20.39317 -3.53 0.000 -111.8914 -31.95162
_cons | 3194.808 55.04911 58.04 0.000 3086.913 3302.702
--------------+----------------------------------------------------------------
OME1 |
mage | -5.068833 5.954425 -0.85 0.395 -16.73929 6.601626
prenatal1 | 34.76923 43.18534 0.81 0.421 -49.87248 119.4109
mmarried | 124.0941 40.29775 3.08 0.002 45.11193 203.0762
fbaby | 39.89692 56.82072 0.70 0.483 -71.46966 151.2635
_cons | 3175.551 153.8312 20.64 0.000 2874.047 3477.054
--------------+----------------------------------------------------------------
TME1 |
mmarried | -.6484821 .0554173 -11.70 0.000 -.757098 -.5398663
mage | .1744327 .0363718 4.80 0.000 .1031452 .2457202
|
c.mage#c.mage | -.0032559 .0006678 -4.88 0.000 -.0045647 -.0019471
|
fbaby | -.2175962 .0495604 -4.39 0.000 -.3147328 -.1204595
medu | -.0863631 .0100148 -8.62 0.000 -.1059917 -.0667345
_cons | -1.558255 .4639691 -3.36 0.001 -2.467618 -.6488926
-------------------------------------------------------------------------------
出力のPOmeansセクションは、2つの処理グループのPOMを表示します。ATEは、3173.369 - 3403.336 = -229.967と計算され。
OME0セクションとOME1セクションは、それぞれ未処理群と処理群のRA係数を表示する。
出力のTME1 セクションは、probit 処置モデルの係数を表示する。
前の2つのケースと同様に、もし、標準誤差などを含むATEが欲しければ、ateオプションを指定する。ATETが欲しい場合は、atetオプションを指定する。
AIPW: 拡張逆確率重み付け Augmented inverse probability weighting
IPWRA推定量では、非ランダムな治療割り付けを考慮し、結果と治療の両方をモデル化する。AIPW推定量も同様である。
AIPW推定量は、IPW推定量にバイアス補正項を追加する。治療モデルが正しく規定されていれば、バイアス補正項は0であり、モデルはIPW 推定量に縮小される。もし治療モデルが誤って規定されていても、結果モデルが正しく規定されていれば、バイアス補正項が推定量を修正する。このように、バイアス補正項はAIPW推定量にIPWRA推定量と同じダブルロバスト特性を与える。
AIPW推定量の構文と出力は、IPWRA推定量とほぼ同じである。
teffects aipw (bweight mage prenatal1 mmarried fbaby) ///
> (mbsmoke mmarried c.mage##c.mage fbaby medu, probit) ///
> , pomeans aequations
Iteration 0: EE criterion = 4.632e-21
Iteration 1: EE criterion = 5.391e-26
Treatment-effects estimation Number of obs = 4,642
Estimator : augmented IPW
Outcome model : linear by ML
Treatment model: probit
-------------------------------------------------------------------------------
| Robust
bweight | Coefficient std. err. z P>|z| [95% conf. interval]
--------------+----------------------------------------------------------------
POmeans |
mbsmoke |
Nonsmoker | 3403.355 9.568472 355.68 0.000 3384.601 3422.109
Smoker | 3172.366 24.42456 129.88 0.000 3124.495 3220.237
--------------+----------------------------------------------------------------
OME0 |
mage | 2.546828 2.084324 1.22 0.222 -1.538373 6.632028
prenatal1 | 64.40859 27.52699 2.34 0.019 10.45669 118.3605
mmarried | 160.9513 26.6162 6.05 0.000 108.7845 213.1181
fbaby | -71.3286 19.64701 -3.63 0.000 -109.836 -32.82117
_cons | 3202.746 54.01082 59.30 0.000 3096.886 3308.605
--------------+----------------------------------------------------------------
OME1 |
mage | -7.370881 4.21817 -1.75 0.081 -15.63834 .8965804
prenatal1 | 25.11133 40.37541 0.62 0.534 -54.02302 104.2457
mmarried | 133.6617 40.86443 3.27 0.001 53.5689 213.7545
fbaby | 41.43991 39.70712 1.04 0.297 -36.38461 119.2644
_cons | 3227.169 104.4059 30.91 0.000 3022.537 3431.801
--------------+----------------------------------------------------------------
TME1 |
mmarried | -.6484821 .0554173 -11.70 0.000 -.757098 -.5398663
mage | .1744327 .0363718 4.80 0.000 .1031452 .2457202
|
c.mage#c.mage | -.0032559 .0006678 -4.88 0.000 -.0045647 -.0019471
|
fbaby | -.2175962 .0495604 -4.39 0.000 -.3147328 -.1204595
medu | -.0863631 .0100148 -8.62 0.000 -.1059917 -.0667345
_cons | -1.558255 .4639691 -3.36 0.001 -2.467618 -.6488926
-------------------------------------------------------------------------------
ATEは3172.366 - 3403.355 = -230.989となる。
最終的な考察
上記の例では、出生体重という連続的なアウトカムを使用した。teffectsは、二値、計数、非負の連続的なアウトカムでも使用することができる。
また、推定量では、複数の治療カテゴリーが可能である。
Stata 13のtreatment-effects機能については、マニュアル全体が費やされており、基本的な紹介、高度な議論、そして実例が含まれている。さらに詳しく知りたい方は、Stataのウェブサイトから[TE] Treatment-effects Reference Manualをダウンロードすることができる。 http://www.stata.com/manuals13/te/
参考文献
Cattaneo, M. D. 2010. Cattaneo, M. D. 2010: Efficient semiparametric estimation of multi-valued treatment effects under ignorability. Journal of Econometrics 155: 138-154.