こちらの続き。
こちらの4章の翻訳。
https://cran.r-project.org/web/packages/PSweight/vignettes/vignette.pdf
4.3. 複数の処置法を用いた傾向スコアによる重み付け
セクション4.2で二重処置のケースで提供した構文は,多重処置のケースに継ぎ目なく一般化することができる。したがって,冗長にならないように,このサブセクションの目的は,同じ手順を繰り返さないことである。その代わりに,複数の治療を伴うPSweightの追加的な特徴を指摘することによって,最後のサブセクションを補完する。シンプルにするために,IPWと重複を改善する3つのタイプの重みに焦点を当てることにする. OW、MW、EW(Li and Li 2019)である。
一般化傾向スコアの推計とバランス評価
3水準変数であるDmultを治療対象として使用する。 人口の約半数が高度な学歴を有し、中程度の学歴を有する者と学歴を有しない者がほぼ同数である。また、比率推定量の推定と推論を説明するために、賃金の二値化結果であるwagebinを用いる。この二値化された賃金は、19913年の30-39歳のイギリス人男性労働者の平均時給のカットオフ値として得られた。平均時給は8.23円であり、log(8.23) ≒ 2.10をカットオフとした。平均時給を上回る者は1610人、下回る者は2032人であり、平均時給を上回るための学歴の一対(加重)平均治療効果を推定することに関心がある。
一般化傾向スコアを推定するために,二値治療の場合と同じ共変量セットを用いて,多項式回帰モデルps.multを指定する.
ps.mult <- Dmult ~ white + maemp + as.factor(scht) + as.factor(qmab) + as.factor(qmab2) + as.factor(qvab) + as.factor(qvab2) + paed_u + maed_u + agepa + agema + sib_u + paed_u*agepa + maed_u*agema
そして、傾向スコア推定値を得て、SumStat()関数で重み付き共変量バランスを評価する。 このコンポーネントは、一般化傾向スコアを可視化するために密度プロットのみを許可する(ヒストグラムは許可しない)ことを除いて、2値処置のケースと同様である.具体的には、type = "hist "を指定しても、plot.SumStat()関数は密度プロットを返す。この場合,"Histogram only available for binary treatment "という警告メッセージが生成される。
bal.mult <- SumStat(ps.formula = ps.mult,
weight = c("IPW", "overlap", "matching", "entropy"),
data = NCDS)
plot(bal.mult, type = "hist")



Warning message: Histogram only available for binary treatment. Density plot provided instead.
一般化傾向スコアの分布を図3に示す(治療群名のアルファベット順)。 advanced qualification (">=A/eq") または no qualification ("None") を受ける一般化傾向スコアについては、グループ固有の分布が分離しているため、重複が軽度に欠如していることがわかる。bal.multには4つの重み付けスキームが含まれているので、最大ペアワイズASDをプロットし、(重み付け)共変量バランスを1つのLoveプロットで評価かる。
plot(bal.mult, metric = "ASD")
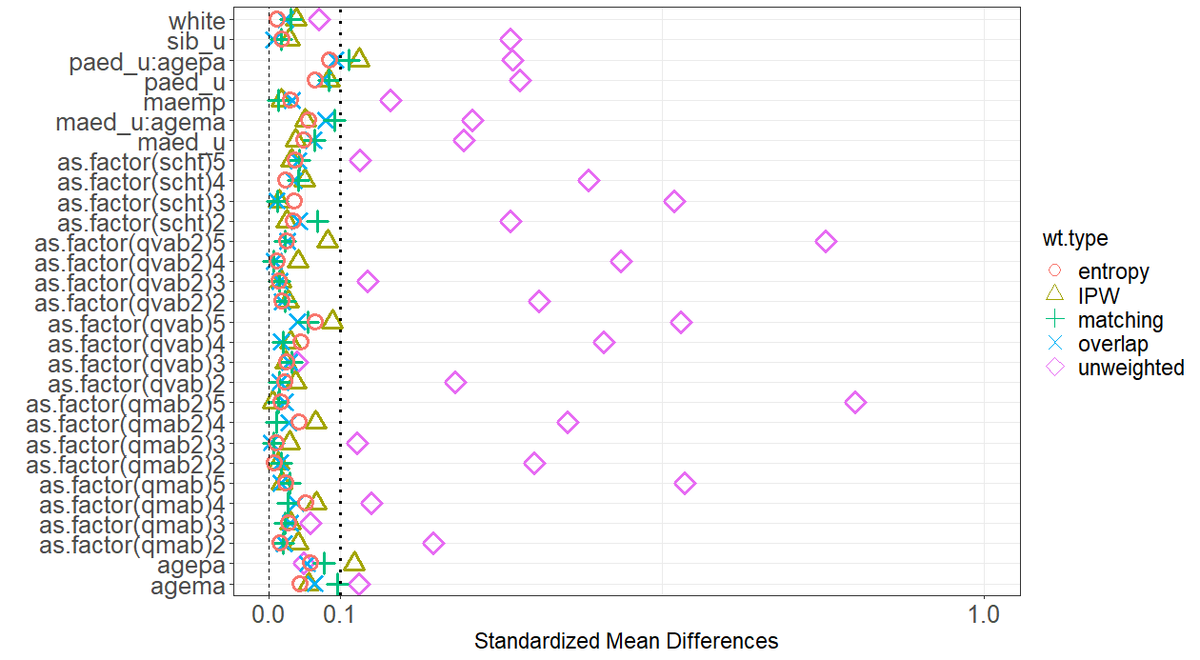
共変量は重み付けをする前に3つのグループ間でアンバランスになっている。IPWは一般的に共変量バランスを改善することができまる、重複の不足により最大ペアワイズASDはまだ時々閾値0.1を超えることがある。一方、OW、MW、EWはいずれも重複が改善された部分母集団を強調し、すべての共変量にわたってより良いバランスを提供する。
一般化傾向スコアのトリミング
PSweightパッケージは、(一般化された)傾向スコアに基づいてトリミングを行うことができる。IPWは、図4の3つのグループ間の共変量を十分にバランスさせないので、IPWのバランスを改善する方法としてトリミングを検討する。PSweightパッケージによって実行されるトリミングには、(1)極端な(一般化傾向スコア)を持つユニットを削除する対称トリミング(Crump et al.2009;Yoshida et al. 2018)と、(2)(ペアワイズ)ATEを推定するための最もffiient IPW推定量を提供する最適トリミング(Crump et al.2009; Yang et al. 2016)の2種類がある。具体的には、対称的なトリミングは、デルタ引数を通じてSumStat()とPSweight()関数の両方によってサポートされている。両関数とも、Li et al. (2019)の推奨に従ってトリミング後に(一般化)傾向スコアモデルを再フィットする。また、対称トリミングと最適トリミングの両方を実行するスタンドアロンPStrim関数も提供する。 Yoshida et al. (2018)に従い、3つの治療群で、推定された一般化傾向スコアがδ = 0.067より小さいすべての個体を除外する。この閾値は、advanced qualification グループのかなりの量の個体を除去する(情報は、SumStatオブジェクトのtrim要素から引き出すことができる)。 Yoshida et al. (2018)で議論されているように、傾向トリミングはATEとATTの推定を改善することができるが、ATOとATMの推定にはほとんど影響を及ぼさない。明らかに、図5は、トリミングされたサンプルにおいて、IPWがすべてのペアワイズASDを10%以内に制御していることを示している。また、OW、MW、EWについては、トリミングによる加重バランスへの影響はほとんどなかった。
bal.mult.trim <- SumStat(ps.formula = ps.mult,
weight = c("IPW", "overlap", "matching", "entropy"),
data = NCDS, delta = 0.067)
bal.mult.trim
1050 cases trimmed, 2592 cases remained
trimmed result by trt group:
>=A/eq None O/eq
trimmed 778 71 201
remained 1028 824 740
weights estimated for: IPW overlap matching entropy
plot(bal.mult.trim,metric = "ASD")
 図5:δ=0.067の対称トリミング後の、最大ペアワイズASDメトリックを用いた3レベル処理変数Dmultのラブプロット。このプロットは、PSweightパッケージのplot.SumStat()関数によって生成されたもの。
図5:δ=0.067の対称トリミング後の、最大ペアワイズASDメトリックを用いた3レベル処理変数Dmultのラブプロット。このプロットは、PSweightパッケージのplot.SumStat()関数によって生成されたもの。
また、トリミングの閾値を指定しない場合、PStrim関数はデータに基づいて最適な閾値を特定する最適トリミング手順をサポートする。 構文の例を以下に示す。トリミングの要約統計量を引き出すと、最適トリミングでは、上級資格者、中級資格者、無資格者において、それぞれ27%、9%、2%が除外されていることがわかる。 この排除はδ=0.067の対称的トリミングと比較してより保守的である。しかし、最適トリミング後の共変量バランスは、図5と同様であり、省略した。
PStrim(ps.formula = ps.mult, data = NCDS, optimal = TRUE)
Summary of the trimming:
>=A/eq None O/eq
trimmed 479 21 82
remained 1327 874 859
一組の(加重)平均治療効果の推定と推論
2.5節で紹介した比率推定量をバイナリーアウトカムのwagebinを用いて推定する。ここでは、説明のために、トリミングを行わないデータに基づいて因果効果を推定するのみであり、トリミングしたデータによる解析も全く同じ手順で行う。 多項ロジスティック傾向スコアモデルに基づいて、IPWにより結合母集団における一対の因果関係RRを求める。
ate.mult <- PSweight(ps.formula = ps.mult, yname = "wagebin", data = NCDS,
weight = "IPW")
contrasts.mult <- rbind(c(1,-1, 0), c(1, 0,-1), c(0, -1, 1))
sum.ate.mult.rr <- summary(ate.mult, type = "RR", contrast = contrasts.mult)
sum.ate.mult.rr
Closed-form inference:
Inference in log scale:
Original group value: >=A/eq, None, O/eq
Contrast:
>=A/eq None O/eq
Contrast 1 1 -1 0
Contrast 2 1 0 -1
Contrast 3 0 -1 1
Estimate Std.Error lwr upr Pr(>|z|)
Contrast 1 0.607027 0.115771 0.380120 0.83393 1.577e-07 ***
Contrast 2 0.459261 0.052294 0.356767 0.56176 < 2.2e-16 ***
Contrast 3 0.147766 0.121692 -0.090746 0.38628 0.2246
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
適切な対比行列を用意し、summary.PSweight()関数で対数スケールでの平均値の比較を行い、対比ベクトルaに対してを推定する。p値は、弱い因果関係の帰無仮説
に対する統計的証拠を提供する。その結果、複合母集団において、全員が高学歴の場合、平均以上の時給を受け取る割合は、全員が無学歴の場合のexp(0.607)=1.83倍となることが分かった。また、全員が上級資格を取得したときに平均以上の時給を受け取る割合は、全員が中級資格を取得したときのexp(0.459)=1.58倍である。両効果とも0.05水準で有意であり、対応する因果の帰無に対して強い証拠を与える(p値<0.001)。しかし、全員が中級の資格を取得した場合、平均以上の時間給を受け取る割合は、資格のない場合と比較してわずかに高くなるだけであり、p値は0.05を超えた。因果関係RRとその信頼区間を直接報告するには、summary.PSweight()関数によって提供される点推定値と信頼区間を単純に指数化すればよい。
exp(sum.ate.mult.rr$estimates[,c(1,4,5)])
Estimate lwr upr Contrast 1 1.834968 1.4624601 2.302358 Contrast 2 1.582904 1.4287028 1.753749 Contrast 3 1.159241 0.9132496 1.471493
観察された共変量において最も重複する標的集団に焦点を当てて,著者らはさらに対の因果的RRを推定するためにOWを使用した。OWは、対比較のための最良の内部妥当性を理論的に提供する;図5はまた、OWが重複集団間のより良好な共変量バランスを達成することを示す。サマリーによって提供される結果の指数。PSweight () 関数を用いて,各ペアワイズ因果RRが重複加重集団の中で大きな効果サイズを持つことを観察した。興味深いことに、重複集団の中では、誰もが中間的な資格を取得したときに平均以上の時間給を受け取る割合は、誰もが学術的な質を獲得していないときの約1.55倍になり、関連する95% CIは無効を除外する。更に,一対比較に対する標準誤差は, OW対IPWを用いた場合,より小さく, OW分析は,等平衡を有するポピュレーションに焦点を絞ることにより,一般的に増加した力に相当することを示した。MWとEWの両方を使用して分析を繰り返す;この解析の結果はOWに類似しているため、簡略化のため省略している。
ato.mult <- PSweight(ps.formula = ps.mult, yname = "wagebin", data = NCDS,
weight = "overlap")
sum.ato.mult.rr <- summary(ato.mult, type = "RR", contrast = contrasts.mult)
exp(sum.ato.mult.rr$estimates[,c(1,4,5)])
Estimate lwr upr Contrast 1 2.299609 1.947140 2.715882 Contrast 2 1.527931 1.363092 1.712705 Contrast 3 1.505048 1.257180 1.801785
上記の結果は、重複集団の中で、高度な資格認定と中間的な資格認定とを比較した因果RRは、中間的な資格認定と資格なしとを比較した場合と同様の大きさであることを示唆している。帰無仮説:
(セクション2.5も参照)に基づいて、2つの連続した原因RRの等価性を形式的にテストすることができる。操作上、対応するコントラストベクトルcontrast
=c(1、1、-2)を指定する必要がある。この帰無仮説ほテストするためのp値は0.91(簡潔にするために出力を省略)であり、0.05レベルでの連続的因果RRの同等性に対する証拠の欠如を示唆する。
summary(ato.mult, type = "RR", contrast = c(1, 1, -2), CI = FALSE)
Closed-form inference:
Inference in log scale:
Original group value: >=A/eq, None, O/eq
Contrast:
>=A/eq None O/eq
Contrast 1 1 1 -2
Estimate Std.Error z value Pr(>|z|)
Contrast 1 0.01509 0.12821 0.11769 0.9063
sum.ato.mult.or <- summary(ato.mult, type = "OR", contrast = contrasts.mult) exp(sum.ato.mult.or$estimates[,c(1,4,5)])
Estimate lwr upr Contrast 1 3.586050 2.841383 4.525879 Contrast 2 2.050513 1.696916 2.477791 Contrast 3 1.748855 1.375483 2.223578
最後のステップとして, OWを結果回帰と組み合わせる方法を説明し,重複集団間のペアワイズ因果RRを推定した。4.2節と同様に、二項結果回帰モデルでも同じ共変量の集合を用いる。
out.wagebin <- wagebin ~ white + maemp + as.factor(scht) + as.factor(qmab) +
as.factor(qmab2) + as.factor(qvab) + as.factor(qvab2) + paed_u + maed_u +
agepa + agema + sib_u + paed_u * agepa + maed_u *agema
この結果の回帰式をPSweight () 関数にロードし、family="binomial"を指定して結果の種類を指定すると、logRRスケールで拡張された重複重み付け推定値が得られる。点推定値と信頼限界を乗じると、1対の因果的RRが報告される。拡張OW推定器により報告されたペアワイズ因果RRは単純OW推定器により報告されたものと類似している;さらに、信頼区間の幅もアウトカム増強の前後で同等であり、ペアワイズRRに基づく因果関係の結論は変わらない。単純なOW推定器と拡張OW推定器の間の類似性は, OWそれ自身が既に効率的であるかもしれないことを意味する。
ato.mult.aug <- PSweight(ps.formula = ps.mult, yname = "wagebin", data = NCDS,
augmentation = TRUE, out.formula = out.wagebin, family = "binomial")
sum.ato.mult.aug.rr <- summary(ato.mult.aug, type = "RR",
contrast = contrasts.mult)
exp(sum.ato.mult.aug.rr$estimates[,c(1,4,5)])
Estimate lwr upr Contrast 1 2.310628 1.957754 2.727105 Contrast 2 1.540176 1.375066 1.725111 Contrast 3 1.500237 1.253646 1.795331
4.4. 機械学習を使用した傾向スコアと潜在的な成果の推定
既定の一般化された線形モデルの代わりに、より高度な機械学習モデルを使用して傾向スコアと潜在的な結果を推定できる。柔軟な傾向スコアと結果推定は,モデルのミス・スペシフィケーションによるバイアスを低減し,共変量バランスを潜在的に改善することが示されている (Lee, Lessler and Stuart 2010;Hill 2011;McCaffrey et al.2013) 。これは、この方法を一般化ブーストモデル (GBM)またはSuperLearnerの方法として指定することにより、バランスチェックと構造化重み付き推定器の両方に対してPSweightで実現できる。これらのメソッドの追加のモデル仕様は、ps.controlとout.controlで提供できる。gbmにもSuperLearnerにも含まれていない機械学習モデルは、外部から推定し、ps.estimateおよびout.estimate引数を使用してインポートできる。これらの2つの議論は、傾向スコアの外部からの推定値とpotential outcomeモデルを容易に組み込むことができる場合に、PSweightの有用性を広げる。
ここでは、デフォルトの一般化線形モデルの代替としてGBMを使用する方法について説明する。この図は、二項教育 「Dany」に基づいている。GBMは,予測因子と転帰(Friedman、Hastie、Tibshirani 2000)の間の柔軟な非線形関係を可能にするノンパラメトリックツリーに基づく回帰のファミリーである。次の傾向モデル式が指定されている。ブースト回帰はすでに非線形効果と相互作用(McCaffrey, Ridgeway, and Morral (McCaffrey, Ridgeway, and Morral 2004))を捉えることができるため、式には相互作用項は含まれない。この図では、AdaBoost (Freund and Schapire 1997) アルゴリズムを使用して、制御設定ps.control=list (distribution="adaboost") によって傾向モデルを適合させている。ツリー数 (n.trees=100) 、相互作用深さ (interaction.depth=1) 、終端ノードの最小観測数 (n.minobsinnode=1) 、収縮低減 (shrinkage reduction=0.1) 、および袋詰め率 (shrinkage=0.5)など、他のモデルパラメータには既定値を使用する。これらのパラメーターの代替値は、ps.controlを介して渡すこともできる。
ps.any.gbm <- Dany ~ white + maemp + as.factor(scht) + as.factor(qmab) +
as.factor(qmab2) + as.factor(qvab) + as.factor(qvab2) + paed_u +
maed_u+ agepa + agema + sib_u
bal.any.gbm <-SumStat(ps.formula = ps.any.gbm, data= NCDS, weight = "overlap",
method = "gbm", ps.control = list(distribution = "adaboost"))
plot.SumStat()`によるバランスチェックでは、重み付け後のすべての共変量のSMDが0.1以下となり、共変量バランスが大幅に改善されたことが示された。 バランスを評価し、傾向スコアモデルの妥当性を確認した後、我々はさらにデフォルトのロジスティック回帰とパラメータを用いて、GBMを用いてアウトカムモデルを推定する。 PSweight()関数では、ps.method = "gbm" と out.method = "gbm "の両方を指定し、out.control引数はデフォルトのままにしておくことができる。 詳細なコードと出力の要約は以下の通りである。 GBMはデフォルトで共変量間の相互作用を考慮するため、ここでは相互作用項を用いずに傾向スコアモデルを再定義している。 GBMを用いた結果は、一般化線形モデルを用いた結果と非常によく似ている。
out.wage.gbm <- wage ~ white + maemp + as.factor(scht) + as.factor(qmab) + as.factor(qmab2) + as.factor(qvab) + as.factor(qvab2) + paed_u + maed_u + agepa + agema + sib_u ato.any.aug.gbm <- PSweight(ps.formula = ps.any.gbm, yname = "wagebin", data = NCDS, augmentation = TRUE, out.formula = out.wage.gbm, ps.method = "gbm", ps.control = list(distribution = "adaboost"), out.method = "gbm") summary(ato.any.aug.gbm, CI = FALSE)
Using 100 trees...
Using 100 trees...
Closed-form inference:
Original group value: 0, 1
Contrast:
0 1
Contrast 1 -1 1
Estimate Std.Error z value Pr(>|z|)
Contrast 1 0.187532 0.018462 10.158 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
5. 概要
傾向スコア重み付けは因果推論と比較有効性研究のための重要なツールである。本論文では、PSweightパッケージを紹介し,二値および複数の治療群の状況でNCDSデータ例を用いてその機能を示した。PSweightは、観察研究のデザインを支援するための読みやすいバランス統計とプロットを提供するだけでなく、加法スケールと比率スケールの両方に対する (加重された) 平均処理効果について、様々な加重スキームを用いた点と分散の推定も提供する。これらの重み付けスキームはLiら (2018) 及びLiとLi (2019) で最近導入された最適重複重みを含み,等姿勢での集団間の有効な因果比較有効性証拠の生成を助けることができた。
PSweightパッケージは、傾向スコア重み付け分析のための他の有用なコンポーネントを含めるために継続的に開発されている。具体的には、PSweightの将来のバージョンには、バランシングウェイトと柔軟な変数選択ツール(Yang, Lorenzi, Papadogeorgou, Wojdyla, Li, and Thomas 2020)を使用して、事前に指定されたサブグループ分析を可能にするコンポーネントが含まれる。また、イベントまでの時間の結果と複雑な調査デザインを持つ重複重み付け推定器を研究している。これらの新機能は,方法論の拡張と同時に活発に開発されている。