Stataで潜在クラス分析をする方法を今まで2回エントリしている。
以前のエントリでも書いているが、Stata標準機能(https://www.lightstone.co.jp/stata/capabilities_latent_class_analysis.html)の潜在クラス分析は必要な機能が足りていない。そこで、Lanzaのグループが作成したプラグインを用いる。
今回はBLRT: bootstrap likelihood ratio test(ブートストラップ尤度比検定)のやり方を説明する。
ダウンロードするもの
LCA Stata plugin
https://www.latentclassanalysis.com/software/lca-stata-plugin/
LCA Bootstrap Stata
https://www.latentclassanalysis.com/software/lca-bootstrap-stata/
ユーザーズガイド
参考までに。今回のエントリと同じ例を取り上げている。
説明例
bootstrap-example2.doを用いる。
LCA Bootstrap Stataプラグインのzipファイル内に含まれている。
プラグインの配置
LCA Stata PluginとLCA Bootstrap Stata Functionを解凍し、全ファイルを同じディレクトリに入れておく。場所は任意だ。
adoファイルの書き換え
LCA Stata Pluginを稼働させるためにdoLCA.adoの中を書き換えlca.dllのパスを設定する必要がある。
最終行(今回は967行目)に下記のように書かれてある。
program lca, plugin using("D:\project\Stata_lca\Release-1.3.2\lca.dll")
using()の中をプラグインを配置したディレクトリに書き換える。
ディレクトリパスに1つ以上のスペースがある場合、Stataの規則に従って、パスを二重引用符で囲む必要があるので注意。
doファイルの書き換え
BLRTのdoファイルを書き換える必要がある。今回はbootstrap-example2.doを使うので、その4行目にプラグインを配置した場所を書く必要がある。デフォルトは下記のような記載になっている。
cd D:\project\Stata_lca\LcaBootstrap-32bit\ /*CHANGE THIS PATH TO MATCH THE FILE LOCATION ON YOUR MACHINE!*/
adoファイルの書き換えと同じことをdoファイルでも行う。
データの場所の記載
データはプラグインと同じフォルダに入れておく。bootstrap-example2.doの6行目で指定する。
infile using delinquency2
今回は例の通りdelinquency2を使用する。自身の分析をする時には、ここを書き換える。
データについて
Collins and Lanza (2010)の11-12ページに示された思春期の非行行動の例におおむね基づいている。N = 2000の青少年の5つのアンケート項目(乱暴者rowdy、破壊者vandal、万引きshoplift、盗みsteal、喧嘩fight)の回答に基づいている。最初に2クラス、次に3クラスのモデルがデータに適合される。ブートストラップ尤度比検定は、2クラス・モデルが3クラスの代替モデルに対して適切であるかどうかを検定するために使用される。
2クラスモデル
8-13行目。BLRTで比較したい小さい方のモデルについて書く。適宜nclass(2)のところを書き換える。
qui doLCA Rowdy Vandal Shoplift Steal Fight, ///
nstart(10) ///
nclass(2) ///
freq(Count) ///
seed(1000) ///
categories(2 2 2 2 2)
3クラスモル
35-41行目。こちらはBLRTで比較する大きい方のモデル。適宜nclass(3)と書いておく。
qui doLCA Rowdy Vandal Shoplift Steal Fight, ///
nstart(10) ///
nclass(3) ///
freq(Count) ///
seed(1000) ///
categories(2 2 2 2 2)
local alt_logliks = r(loglikelihood)
BLRT
Line48-58。LCA Bootstrap Stata機能を実行し、2クラスモデルと3クラスモデルの相対的な適合度を比較し、p値を表示する。
下記の部分が該当箇所だが、今回は変更しなくてよい。
doLcaBootstrap, ///
null_gammalist(`glist') ///
null_rholist(`rholist') ///
null_loglikelihood(`null_logliks') ///
alt_loglikelihood(`alt_logliks') ///
simulate_samplesize(10000) ///
num_bootstrap(99) ///
null_nstarts(10) ///
alt_nstarts(10)
dis e(p_value)
結果(2class vs. 3class)
計算時間はわりとかかる。また出力される結果もかなり長い。
. dis e(p_value) .01
p値は0.01で、2クラスモデルが制約され過ぎていることを意味しているとマニュアルでは書かれてあるが、平たく言えば、2クラスモデルより、3クラスモデルの方がモデルの改善がされているということである。
上記のブートストラップの設定をみると、99回になっている。ブートストラップ法はランダムなところがあるため、同じデータでもp値が全く同じになるとは限らないことに注意が必要だ。p値のランダムなばらつきを減らすにはnum_bootstrapのところを増やして、例えばnum_bootstrap(999)にするとよいだろう。
コンピューターの計算が速くなった現代ではブートストラップを999回すのが標準的だが、今回紹介しているプラグインLCA Bootstrap Stata Functionの計算は遅い(最適化されていない)ため、時間がかかり、このプラグインを使うべきか、999回回すべきかは、考えものである。
ブートストラップの回数に関しては下記のエントリを参照してほしい。
https://ides.hatenablog.com/entry/2019/11/25/195627
https://ides.hatenablog.com/entry/2019/11/21/174606
99回だと1%水準までしか疑似P値が計算できないが、999回だと0.1%水準まで疑似P値が計算できるので、999回の方が望ましいのは間違いない。
MplusやLatentGOLDが使えない場合には、Stataを使うしかないので、このプラグインを使うことになるだろう。その時には、最終的な分析の際に、選択するクラス数の前後(今回の例だと4クラスと5クラス)は999回しておいた方が良いだろう。予備分析では99回でも多くのケースでは問題なく計算できる。実際の分析では、99回でも999回でも大きく値が変わるということはあまりないからだ。
結果
さて、p-valueが0.05以上になるところまで同じ作業を反復すると、下記のようになる。
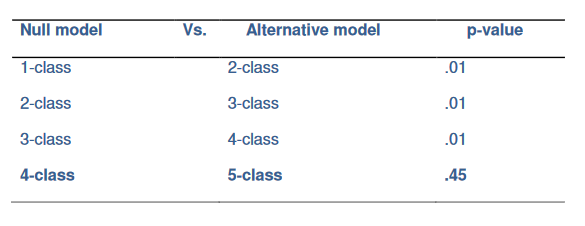
ここで、ブートストラップ尤度比検定に基づいて、思春期の非行行動の潜在クラス数を選択するための逐次分析が行われたとする。理論的な結果は下表のようになる。尤度比検定の統計量では、4クラスモデルと5クラスモデルの間に差が検出されなかったので、思春期の非行行動の4クラスモデルを選択する。