以前にポストしたRのmclustライブリーでの分析はこちら。
例題
今回はMplusのUser's Guideの例をそのまま使う。
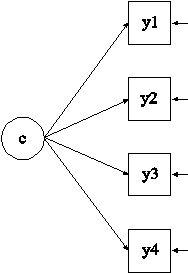
例7.3の連続潜在クラス指標を用いたLCAで、ランダムスタートによる自動開始値を用いたものである。
Mplusの解説
この例と例7.3の違いは、潜在クラス指標がバイナリ変数ではなく、連続変数であることだ。 VARIABLEコマンドで従属変数のスケールに関する指定がない場合、連続変数であることが仮定される。 連続的な潜在クラス指標を用いた潜在クラス分析は、しばしば潜在プロファイル分析と呼ばれる。
自動開始値を使用する場合は、MODELコマンドは指定する必要がない。 潜在クラス指標の平均と分散、およびカテゴリ潜在変数の平均は、デフォルトで推定される。 潜在クラス指標の平均は、デフォルトのようにクラス間で等しく保持されない。 分散は、デフォルトとしてクラス間で等しく保持され、潜在クラス指標間の共分散は、デフォルトとしてゼロで固定される。 このタイプの分析のデフォルトの推定量は、ロバスト標準誤差を持つ最尤推定量である。 ANALYSISコマンドのESTIMATORオプションを使用すると、別の推定量を選択することができる。 他のコマンドの説明は例題7.1および7.3にある。
コード例
データはこちらから。 https://www.statmodel.com/usersguide/chapter7.shtml
TITLE: this is an example of a LCA with continuous latent class indicators using automatic starting values with random starts DATA: FILE IS ex7.9.dat; VARIABLE: NAMES ARE y1-y4; CLASSES = c (2); ANALYSIS: TYPE = MIXTURE; OUTPUT: TECH11 TECH14;
結果
モデルフィット
MODEL FIT INFORMATION
Number of Free Parameters 13
Loglikelihood
H0 Value -3177.162
H0 Scaling Correction Factor 0.9709
for MLR
Information Criteria
Akaike (AIC) 6380.324
Bayesian (BIC) 6435.114
Sample-Size Adjusted BIC 6393.851
(n* = (n + 2) / 24)
エントロピー
CLASSIFICATION QUALITY
Entropy 0.909
クラス比率
FINAL CLASS COUNTS AND PROPORTIONS FOR THE LATENT CLASSES
BASED ON THEIR MOST LIKELY LATENT CLASS MEMBERSHIP
Class Counts and Proportions
Latent
Classes
1 238 0.47600
2 262 0.52400
モデルの結果
MODEL RESULTS
Two-Tailed
Estimate S.E. Est./S.E. P-Value
Latent Class 1
Means
Y1 -1.056 0.070 -15.030 0.000
Y2 -1.088 0.067 -16.255 0.000
Y3 -0.943 0.063 -15.050 0.000
Y4 -1.093 0.074 -14.688 0.000
Variances
Y1 1.134 0.073 15.610 0.000
Y2 0.975 0.063 15.582 0.000
Y3 0.992 0.064 15.483 0.000
Y4 1.007 0.064 15.683 0.000
Latent Class 2
Means
Y1 1.037 0.070 14.762 0.000
Y2 1.004 0.064 15.682 0.000
Y3 0.865 0.068 12.763 0.000
Y4 0.980 0.060 16.321 0.000
Variances
Y1 1.134 0.073 15.610 0.000
Y2 0.975 0.063 15.582 0.000
Y3 0.992 0.064 15.483 0.000
Y4 1.007 0.064 15.683 0.000
LMR
OUTPUT: TECH11を入れると計算してくれる。
VUONG-LO-MENDELL-RUBIN LIKELIHOOD RATIO TEST FOR 1 (H0) VERSUS 2 CLASSES
H0 Loglikelihood Value -3550.694
2 Times the Loglikelihood Difference 747.063
Difference in the Number of Parameters 5
Mean 3.380
Standard Deviation 8.255
P-Value 0.0000
BLRT
OUTPUT: TECH14を入れると計算してくれる。
PARAMETRIC BOOTSTRAPPED LIKELIHOOD RATIO TEST FOR 1 (H0) VERSUS 2 CLASSES
H0 Loglikelihood Value -3550.694
2 Times the Loglikelihood Difference 747.063
Difference in the Number of Parameters 5
Approximate P-Value 0.0000
Successful Bootstrap Draws 5
LMRとBLRTの説明はこちらのエントリーで
まとめ
基本的には潜在クラス分析と大きな違いはないが、モデル結果のところがカテゴリカルではなく、連続変数ででるため、グフかした方がわかりやすいかもしれない。
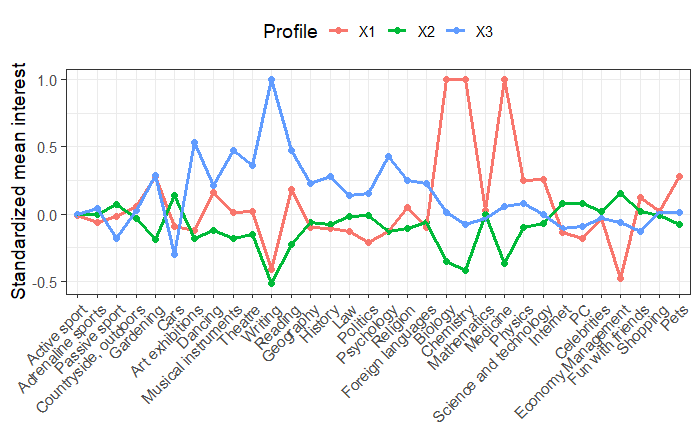
mclusパッケージで作成したのは以下のようなグラフだった。