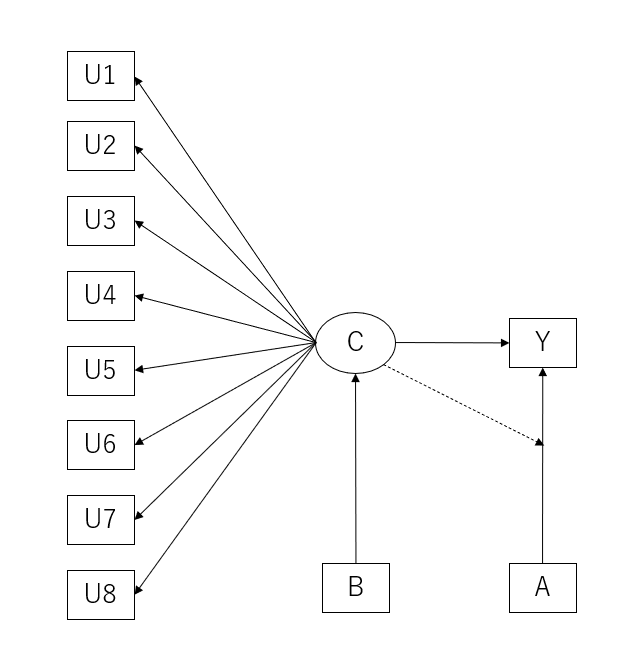
共変量とDistal Outcomesのある潜在クラス分析で、かつ、Distal Outcomesがカテゴリカルな場合の分析である。
モデル
コード
DATA:
FILE = LCA_cat.dat;
VARIABLE:
NAMES = U1-U8 Y A B;
USEVARIABLES = U1-U8 Y A B;
CATEGORICAL = U1-U8 Y;
CLASSES = C(3);
Analysis:
Type = Mixture;
STARTS = 0;
Model:
%overall%
c on B;
Y on A;
%C#1%
Y on A;
%C#2%
Y on A;
%C#3%
Y on A;
CATEGORICALの中にYを入れておく。CATEGORICALの指定は従属変数だけなので独立変数の指定は不要。
仮想データを用いた例題なので開始値を0にしている。
結果
MODEL RESULTS
Two-Tailed
Estimate S.E. Est./S.E. P-Value
Latent Class 1
Y ON
A 0.830 0.000 999.000 999.000
Thresholds
U1$1 -1.224 1.006 -1.217 0.224
U2$1 0.718 1.721 0.417 0.676
U3$1 -0.910 1.160 -0.785 0.433
U4$1 -0.621 0.831 -0.748 0.455
U5$1 1.796 3.291 0.546 0.585
U6$1 26.329 0.000 999.000 999.000
U7$1 -2.116 2.077 -1.019 0.308
U8$1 -3.931 10.865 -0.362 0.718
Y$1 -12.900 0.000 999.000 999.000
Categorical Latent Variables
C#1 ON
B 9047.383 0.000 999.000 999.000
C#2 ON
B 77.074 0.000 999.000 999.000
Distal Outcomesへ回帰はクラスごとに算出(Y ON A)、潜在クラスへの回帰(C ON B)もクラスごとに算出される。潜在クラスへの回帰分析は参照カテゴリが必要なため、2つ値が出力されていて、この場合はC#3が参照カテゴリになっている。
Rでの仮想データの作成
仮想データの作成
set.seed(123) U1 <- sample(0:1, 1000, replace=T,prob=c(0.4,0.6)) U2 <- sample(0:1, 1000, replace=T,prob=c(0.2,0.8)) U3 <- sample(0:1, 1000, replace=T,prob=c(0.5,0.5)) U4 <- sample(0:1, 1000, replace=T,prob=c(0.6,0.4)) U5 <- sample(0:1, 1000, replace=T,prob=c(0.3,0.7)) U6 <- sample(0:1, 1000, replace=T,prob=c(0.9,0.1)) U7 <- sample(0:1, 1000, replace=T,prob=c(0.5,0.5)) U8 <- sample(0:1, 1000, replace=T,prob=c(0.6,0.4)) y <- sample(0:1, 1000, replace=T,prob=c(0.2,0.8)) a <- sample(20:75, 1000, replace=T) b <- sample(0:1, 1000, replace=T,prob=c(0.5,0.5)) d0<- cbind(U1,U2,U3,U4,U5,U6,U7,U8,y,a,b) df <- as.data.frame(d0)
Mplusへの書き出し1
library(MplusAutomation) variable.names(df) # 変数名を書き出し
Mplusへの書き出し2
prepareMplusData(df, filename="LCA_cat.dat",
keepCols=c("U1","U2","U3", "U4", "U5", "U6", "U7", "U8","y","a","b"),
overwrite=T)