LatentGOLDで潜在クラス分析[LatentGOLD]
日本語では潜在クラス分析と呼ぶことが多いが、他の潜在クラスモデルと区別するために、潜在クラス・クラスター・モデル(Latent Class Cluster Model)とも言われる。
データ
RのpoLCAパッケージからvalueデータを使用する。
library("poLCA")
data("values",package="poLCA")
データ
A B C D 1 2 2 2 2 2 2 2 2 2 3 2 2 2 2 4 2 2 2 2 5 2 2 2 2 6 2 2 2 2
データの説明は下記のように書かれている。
「普遍的な価値観」または「特殊な価値観」の傾向を測定する4つの質問(A、B、C、D)に対する216人の回答者の二分法による調査結果。このデータセットは、Goodman (2002, p. このデータセットは、Goodman (2002, p. 14)に表4として掲載されており、以前はGoodman (1974)とStouffer and Toby (1951)に掲載されていた。
サンプルデータなので、特にデータの理解は不要だろう。
havenパッケージでSPSS形式で出力する。
library(haven) write_sav(values, "values.sav")
エリアの呼び方
LatentGOLDの左のエリアはアウトラインペイン、右はコンテンツペインと呼ぶらしい。
データを開く
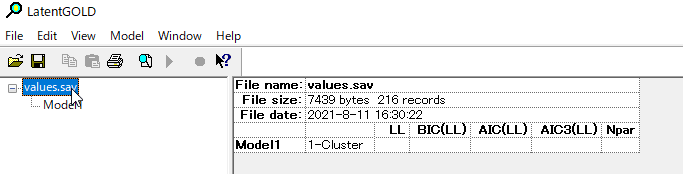
データ名values.savをクリックすると下記のような画面になる。
分析の開始
Model1を右クリック[Cluster]もしくは、メニューの[Model]の[Cluster]をクリックする。
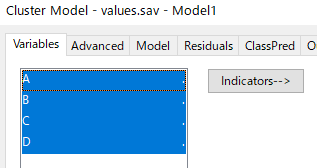
潜在クラス分析を行う変数を[Indicators]の中に入れる。
[Indicators]にいれた後、右クリックし、データタイプを[Nominal]にする。
[scan]を押すと、単純集計がみられるようになる。
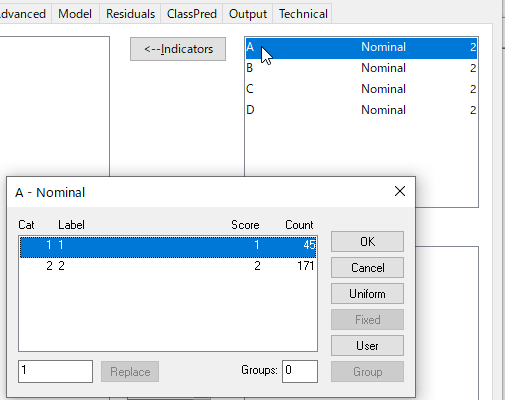
AをダブルクリックするとAの変数の集計が見られる。
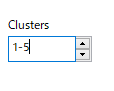
クラスター数の指定
試行錯誤が必要なところだが、とりあえず1から5くらいに指定しておこう。
実行
[Estimete]をクリック。
全体の結果
values.savのところをクリックすると全体の結果がみれる。「イ」となっているのは正しくは2乗表記がされるはずなのだが、バグっている。原因は、使っているWindowsの標準言語を日本語に設定しているためではないかと思っているが、よくわからない。
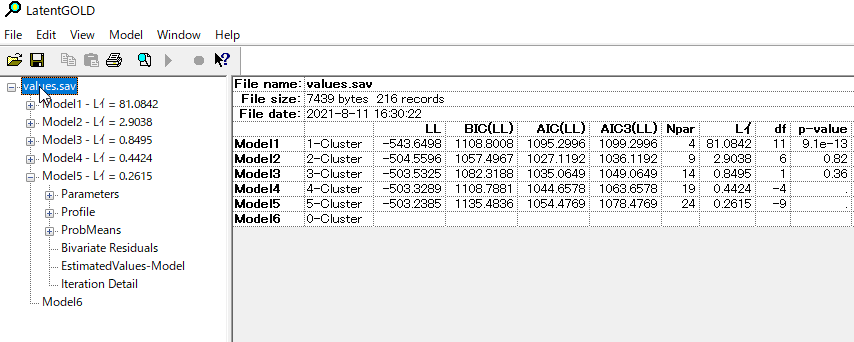
クラス数の決定の解釈1
クラスター数を決定する1つの基準は、L²統計量がカイ二乗分布に従うと仮定した場合の各モデルのp-値を示す「p-値」列を見ることである。一般的には、p値が0.05より大きい(十分な適合性がある)モデルの中で、最も解析的なモデル(パラメータの数が最も少ない(Npar))が選択される。この基準を用いると、最適なモデルはモデル2の2クラスタモデル(p値0.82、Npar=9)となる。
BLRT 条件付きブートストラップによるモデル改善の評価
今回は1クラスと2クラスを比較する。
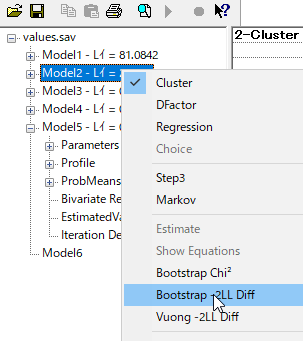
2クラスなので、比較できるのは2と1クラスのみである。

4クラスの場合は3クラスと、一つ少ないクラスと比較するのが通常の使い方である。
結果。

有意であるということは、1クラスより2クラスの方がモデルが改善されているということであるため、BLRTは2クラスモデルを支持していない。5%以上になるまで繰り返そう。
パラメータの出力を見る
パラメータを見るには[+]で開いていく。
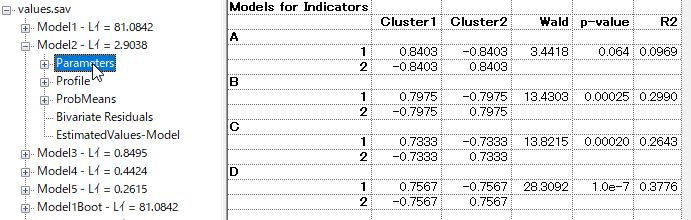
プロフィール
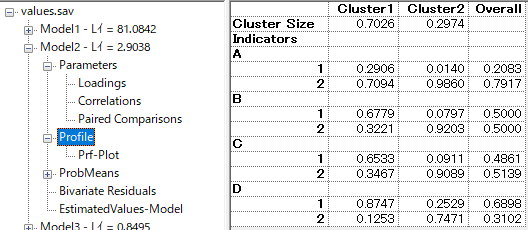
所属クラスと、A-Dの所属確率が表示される。
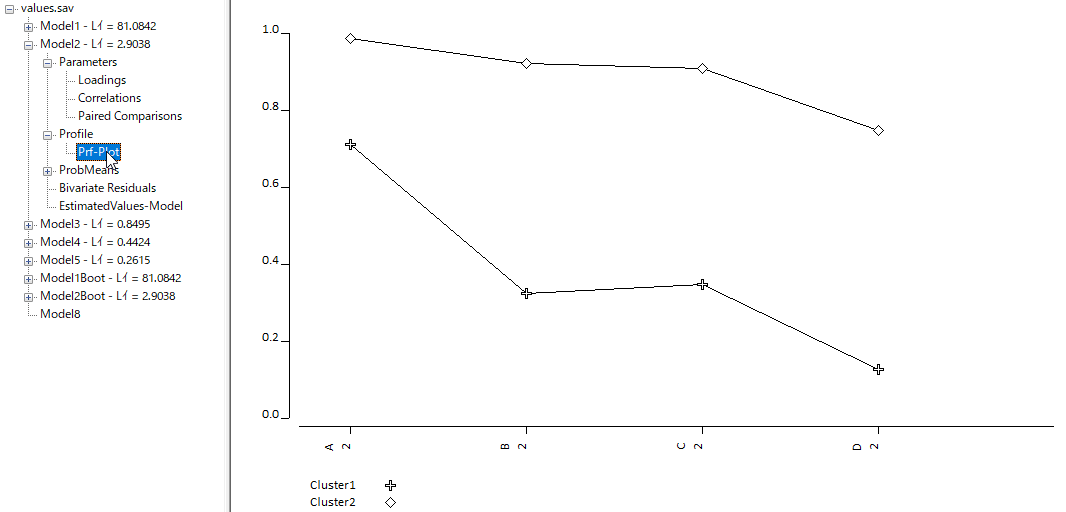
プロフィール・プロット
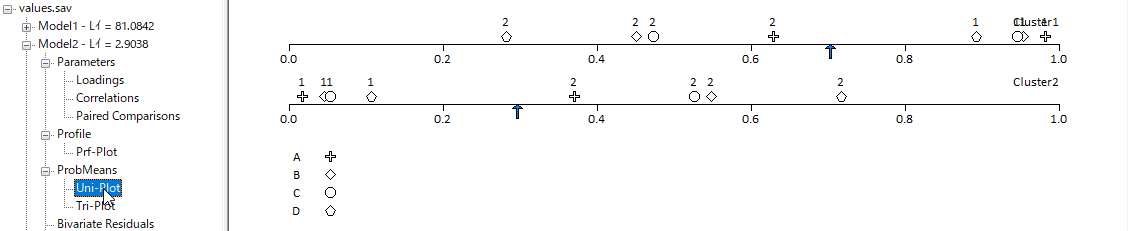
ユニ・プロット
トリ・プロット
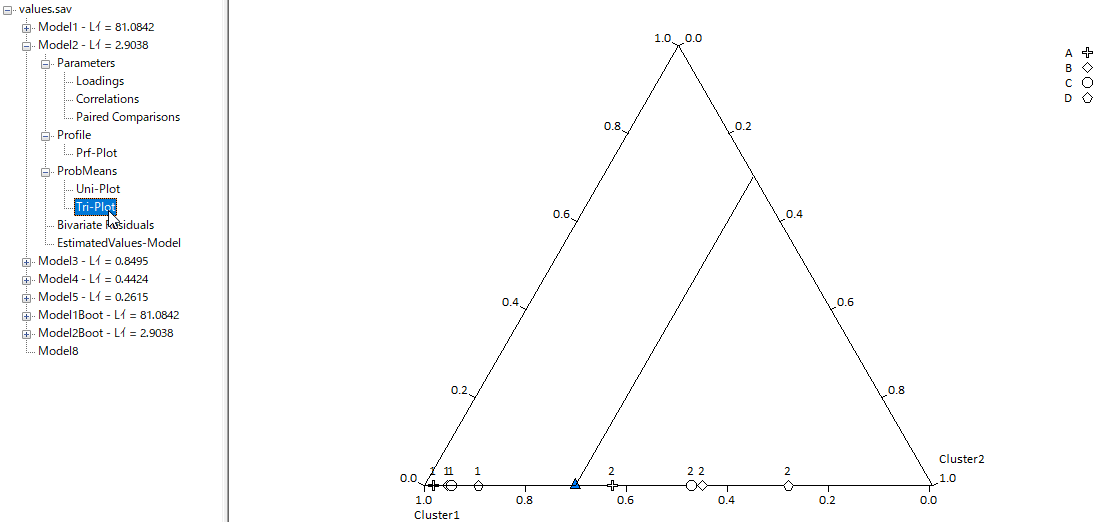
定義ファイルの保存
保存したいモデルを選択し、[File]から定義ファイルを.lgf形式で保存することができる。