RI‐CLPMは従来のCLPMと比較して、個人間の安定的な違い(trait)の影響を分離できる点で優れている。
CLPMは時間的な因果関係を検証するためのモデルであるが、個人ごとの安定した水準の違いが混入するため、変数間の動的な影響が歪められる可能性がある。これに対して、RI‐CLPMはランダム・切片(RI)を導入することにより、各個人の安定した特性を明示的にモデル化することができる。すなわち、各個人の測定値がその人固有の「ベースライン」を持つと仮定し、短期的な変動(状態変動)と個人間の恒常的な違い(特性変動)を分離するというモデルである。
この分離により、RI‐CLPMは以下の点でCLPMよりも信頼性が高いといえる。
因果関係の明確化
個人間の恒常的な差異が除去されるため、各時点における一時的な変動間の因果関係をより正確に評価できる。これにより、実際の動的プロセスを反映した推論が可能となる。バイアスの低減
CLPMでは、個人ごとの定常的なレベルが影響を及ぼし、パス係数の推定がバイアスを受ける恐れがある。RI‐CLPMはその影響を制御するため、パス係数の推定がより信頼できるものとなる。理論的整合性
多くの心理学的・社会科学的理論は、個人間の安定した差異と、時間による一時的な変動を区別して考えることを前提としている。RI‐CLPMはこの理論的前提に則っており、実証研究において理論との整合性を確保できる。
以上のように、RI‐CLPMは個人間の安定差を明示的に考慮することにより、短期的な因果関係の推定においてCLPMよりも精度が高く、解釈が明瞭である。このため、時間的なダイナミクスを正確に捉える必要がある研究において、RI‐CLPMは非常に有用であると言える。
データの読み込み
stataのデータを利用する。
library(rio)
dat<- import("https://raw.githubusercontent.com/JeroenDMulder/RI-CLPM/master/data/RICLPM.dat")
# 変数名を入れる
names(dat) <- c("x1", "x2", "x3", "x4", "x5", "y1", "y2", "y3", "y4", "y5")
モデルの定義と実行
lavaanを用いて、ランダム・切片・クロスラグ・パネル・モデル(RI-CLPM)を定義する。
semPlot()を用いて作成したパス図
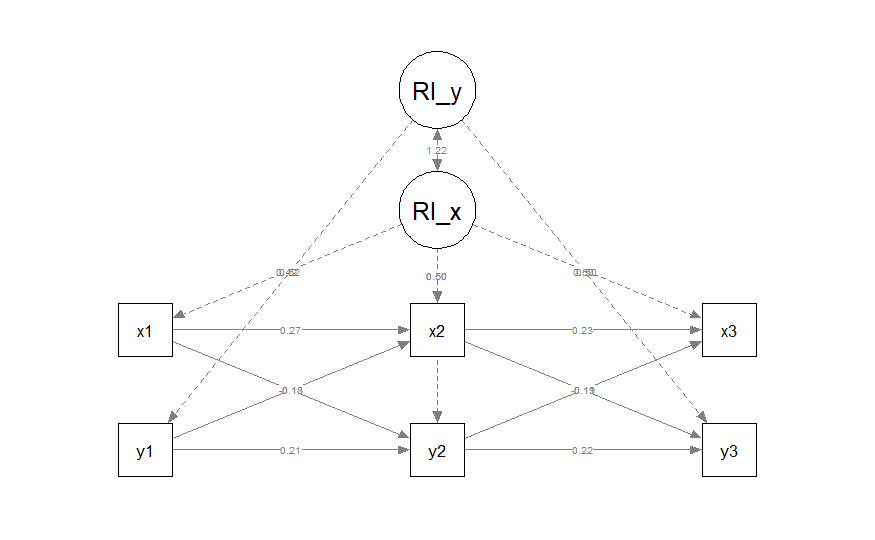
このモデルを定義する。
# モデルの定義 library(lavaan) model <- ' # ランダム切片部分:各変数の安定した個人間差を表す RI_x =~ 1*x1 + 1*x2 + 1*x3 RI_y =~ 1*y1 + 1*y2 + 1*y3 # 自己回帰パス:同じ変数の連続する時点間の影響 x2 ~ a1*x1 x3 ~ a1*x2 y2 ~ b1*y1 y3 ~ b1*y2 # クロスラグパス:異なる変数間の時間的影響 x2 ~ c1*y1 x3 ~ c1*y2 y2 ~ d1*x1 y3 ~ d1*x2 ' # モデルの推定と結果の表示 fit <- sem(model, data = dat) summary(fit, standardized = TRUE)
ランダム・切片(RI)
「RI_x」と「RI_y」は、それぞれxとyの3時点の測定値から、個人ごとに安定している特性(例:性格的傾向など)を表す潜在変数として定義する。
自己回帰パス
同一変数の連続する時点(例:x1→x2、x2→x3)の影響を示し、時間の経過とともにその変数の持続性を評価する。
クロスラグパス
異なる変数間(例:y1がx2に与える影響など)の時間的な影響を評価することで、変数間の相互作用を検討する。 このように、個人間の安定した違いを取り除いた上で、各時点間の因果的関係を明らかにするモデルになっている。
結果
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
RI_x =~
x1 1.000 0.102 0.416
x2 1.000 0.102 0.499
x3 1.000 0.102 0.496
RI_y =~
y1 1.000 0.163 0.519
y2 1.000 0.163 0.495
y3 1.000 0.163 0.498
Regressions:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
x2 ~
x1 (a1) 0.227 0.040 5.686 0.000 0.227 0.272
x3 ~
x2 (a1) 0.227 0.040 5.686 0.000 0.227 0.226
y2 ~
y1 (b1) 0.218 0.040 5.385 0.000 0.218 0.208
y3 ~
y2 (b1) 0.218 0.040 5.385 0.000 0.218 0.219
x2 ~
y1 (c1) -0.119 0.017 -7.111 0.000 -0.119 -0.183
x3 ~
y2 (c1) -0.119 0.017 -7.111 0.000 -0.119 -0.190
y2 ~
x1 (d1) -0.169 0.036 -4.743 0.000 -0.169 -0.125
y3 ~
x2 (d1) -0.169 0.036 -4.743 0.000 -0.169 -0.105
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
RI_x ~~
RI_y 0.020 0.002 12.895 0.000 1.222 1.222
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.x1 0.049 0.003 19.077 0.000 0.049 0.827
.x2 0.028 0.002 15.476 0.000 0.028 0.672
.x3 0.030 0.002 17.122 0.000 0.030 0.712
.y1 0.072 0.004 17.077 0.000 0.072 0.731
.y2 0.072 0.004 17.599 0.000 0.072 0.665
.y3 0.070 0.004 18.701 0.000 0.070 0.659
RI_x 0.010 0.002 5.262 0.000 1.000 1.000
RI_y 0.026 0.004 6.541 0.000 1.000 1.000
解説
1. ランダム・切片(RI)の部分
Latent Variables:
RI_x =~
x1 (Std.all = 0.416)
x2 (Std.all = 0.499)
x3 (Std.all = 0.496)
RI_y =~
y1 (Std.all = 0.519)
y2 (Std.all = 0.495)
y3 (Std.all = 0.498)
- RI_x は x1, x2, x3(同一個人の複数時点の x)に共通する「安定した個人差」を示す潜在変数である。\
- RI_y は y1, y2, y3 に共通する「安定した個人差」になる。\
- ここでは、x1, x2, x3 のすべての因子負荷量を 1 に固定しているため、推定結果としては
Std.allがそれぞれ 0.416, 0.499, 0.496 などの値で出力されている。これは、標準化された観点で「それぞれの時点の x が、どの程度ランダム・切片因子によって説明されているか」の目安になる。
2. 自己回帰パス(自己の過去 → 現在への影響)
x2 ~ x1 (a1) = 0.227(標準化: 0.272) x3 ~ x2 (a1) = 0.227(標準化: 0.226) y2 ~ y1 (b1) = 0.218(標準化: 0.208) y3 ~ y2 (b1) = 0.218(標準化: 0.219)
- x2 \~ x1, x3 \~ x2 は「前時点の x が次時点の x に及ぼす影響」であり、a1 というパラメータで表されている。ここでは 0.227 という同一の値に固定しており、標準化推定値で見ると 0.272 や 0.226 程度の中程度の正の影響があることがわかる。\
- y2 \~ y1, y3 \~ y2 も同様に、前時点の y が次時点の y に及ぼす影響 (b1) で、約 0.218(標準化 0.20 前後)の正の自己回帰効果がある。
要するに、個人間での安定した差(RI)を取り除いた後でも、「同じ変数は前の時点の値が次の時点の値をある程度正に予測している」 という解釈になる。
3. クロスラグパス(他変数の過去 → 現在への影響)
x2 ~ y1 (c1) = -0.119(標準化: -0.183) x3 ~ y2 (c1) = -0.119(標準化: -0.190) y2 ~ x1 (d1) = -0.169(標準化: -0.125) y3 ~ x2 (d1) = -0.169(標準化: -0.105)
- x2 \~ y1, x3 \~ y2 は「前時点の y が次時点の x に与える影響」で、c1 というパラメータでまとめて推定されている。ここでは負の値(-0.119)であり、標準化推定値で -0.18~-0.19 程度の影響がみられる。\
- y2 \~ x1, y3 \~ x2 は「前時点の x が次時点の y に与える影響」で、d1(-0.169)という負の値になっている。標準化推定値で -0.10~-0.13 程度の負の影響がある。
つまり、個人間の安定差を除いて考えた場合、「x と y はお互いに負の影響を与え合っている」 という結果になる。たとえば、ある時点で x がその人にとって相対的に高い場合、次の時点の y はやや低めになる(逆も然り)と解釈できる。
4. ランダム・切片同士の共分散
Covariances: RI_x ~~ RI_y = 0.020(標準化: 1.222)
- RI_x と RI_y の共分散は 0.020 で、標準化指標(相関に相当する値)は約 1.22 とかなり大きい数字である。
- これは、各 RI の分散が非常に小さい(RI_x = 0.010、RI_y = 0.026)ために、相対的な比率として大きくなっていると考えられる。\
- 実質的には「x と y の安定した個人差成分は強い正の相関がある」と見ることができる。
5. 観測変数・潜在変数の分散(Residuals含む)
Variances: .x1 = 0.049(標準化: 0.827) .x2 = 0.028(標準化: 0.672) .x3 = 0.030(標準化: 0.712) .y1 = 0.072(標準化: 0.731) .y2 = 0.072(標準化: 0.665) .y3 = 0.070(標準化: 0.659) RI_x = 0.010(標準化: 1.000) RI_y = 0.026(標準化: 1.000)
- 例えば、x1 の残差分散が 0.049(標準化 0.827)というのは、x1 の分散の約 82.7% は RI_x 以外の要素(短期的変動や誤差など)によるもので、約 17.3% が RI_x(安定した個人差)によって説明されていると読み取れる。\
- x2, x3 はもう少し大きな割合が RI_x で説明されている(標準化残差 0.672, 0.712 → 30% 程度が RI_x )。\
- y1, y2, y3 でも同様に、30~35% 程度が RI_y で説明されている計算になる。\
- RI_x の推定分散が 0.010、RI_y が 0.026 と、y の方が安定差のばらつきがやや大きい結果である。
6. まとめ
RI_x, RI_y(ランダム・切片)
- x, y それぞれに安定した個人差が存在し、さらに両者は非常に強い正の相関を持つ(RI_x \~\~ RI_y の標準化値が大きい)。\
- これは「x がもともと高い人は y も高い」という、個人特性レベルの結びつきを示唆する。
自己回帰パス(a1, b1) - x, y ともに自己回帰効果は正(0.20~0.27 程度)で、前の時点が次の時点の変動を中程度に正に予測する。\ - 安定差(RI)を取り除いた後でも、「x は x 同士、y は y 同士である程度継続性がある」ことを示す。
クロスラグパス(c1, d1)
- いずれも負の値で、x と y は互いに負の影響を与え合う動きがみられる。\
- たとえば「ある時点で x がいつもより高ければ、次の時点では y がやや低めになる」傾向があるという解釈が可能である。\
- ただし効果量はそれほど大きくなく(標準化で -0.10~-0.19 程度)、実際の研究文脈に照らして臨床的・理論的な意味を検討する必要がある。
semPlotによるパス図の作成
library(semPlot) # 変数順を踏まえたレイアウトマトリクスの作成 # (x, y)の座標指定で、それぞれの変数を配置 layout.mat <- matrix(c( 1, 2, # x1 2, 2, # x2 3, 2, # x3 1, 1, # y1 2, 1, # y2 3, 1, # y3 2, 3, # RI_x 2, 4 # RI_y ), byrow = TRUE, ncol = 2) # パス図の描画 semPaths( fit, whatLabels = "std", # 標準化推定値を表示 layout = layout.mat, reorder = FALSE, # カスタム配置をそのまま使う intercepts = FALSE, # 不要な切片ノードを非表示 residuals = FALSE, # 不要な誤差ノードを非表示 nCharNodes = 0, # 変数名が切れないようにする sizeMan = 7, # 観測変数ノードのサイズ sizeLat = 10 # 潜在変数ノードのサイズ )